
介绍
本篇论文提出了一种基于注意力机制的动态head,配合最近大火的强大的swin transformer作为backbone,在coco上首次实现了AP突破60。
摘要
- 问题:之前的一些关于head的工作,致力于提升性能表现而没有提出一个比较统一的视野
- 通过将自注意力机制和谐地融入到 : 特征维度用于尺度感知;空间位置用于位置感知; 通道维度用于任务感知 的理念中,该方法显著地提升了目标检测头的表征能力,并且没有额外计算量负担
- 实验验证了该动态头的有效性和高效性,在COCO数据集上,ResNeXt-1010-DCN backbone达到54AP,使用最新的transformer backbone达到了60AP
介绍
背景
-
背景:目标检测任务:“目标是什么,在哪?”
-
几乎所有检测方法的结构都是:backbone + head
-
head如何设计成为一个有挑战的问题,难点有三:
- scale-aware”:目标大小变化
- “spatial-aware”:目标位置、角度、形状变化
- “task-aware”:目标检测框,中心,角点
-
目前的head还是只能解决这几个问题中的某一个,所以如何设计一个统一的检测头同时解决这些问题是有待研究的。
方法
如果我们考虑一个普通的backbone的输出,我们会得到一个level×space×channel的张量
,所以我们发现设计一个统一的head实际上可以看作是一个注意力学习问题。一个初始的想法就是基于这个张量建立一个完全的自注意力机制。但是,这个优化问题会变得十分难以求解,并且计算量难以承担。
然而,我们可以将注意力机制分解应用到各个维度上去,即:
-
尺度注意力模块 - level维度,用以学习对于对于某个目标的scale而言尺度合适的level
-
空间注意力模块 - space(height×width)维度,用以学习表征在空间位置的差异
-
任务注意力模块 - channel维度,用以将不同的特征通道分配到不同的认为回归中
我们发现,虽然这些注意力模块分别作用在feature的不同维度,但是他们之间的性能可以互补。在COCO数据集上这个方法可以几乎可以给各种目标检测方法提升1.2%~3.2%的AP。
相关工作
-
尺度感知:
-
[6,24,25]:图像金字塔
-
[15]:特征金字塔,问题:不同深度的特征可能存在明显的语义gap
-
[18]:通过自底向上路径增强底层特征
-
[20]:平衡特征金字塔
-
[31]:基于3D卷积统一提取尺度和空间特征
-
-
空间感知:
- [41]:CNN学习空间变换是有局限性的
- [13,32]:通过增加模型size缓解这个问题
- [14]:通过数据增强缓解该问题
- [34]:使用扩展卷积从指数扩展的感受野聚合上下文信息。
- [7]:提出了一种可变形的卷积,通过附加的自学习偏移来采样空间位置。
- [37]:通过引入一个学习的特征幅值来重新表述偏移量,进一步提高了其能力。
-
任务感知:
- [39,6]:最初提出的两阶段结构
- [23]:RPN
- [22]:单阶段
- [16]:任务特定分支
我们的方法
动机
给定一个L层的特征,我们可以通过上采样或下采样的方法将不同level的特征变为中间level的特征尺寸,这样变形后的特征可以表示为一个4维特征张量:L×H×W×C,我们定义S = H×W,将该特征降低到3维:L×S×C,基于这个表征方法,我们探究各个维度的意义:
Dynamic head

注意力作用的表示
$$
W(\mathcal{F})=\pi(\mathcal{F}) \cdot \mathcal{F}
$$
对特征F分别在三个维度使用注意力变换
$$
W(\mathcal{F})=\pi_{C}\left(\pi_{S}\left(\pi_{L}(\mathcal{F}) \cdot \mathcal{F}\right) \cdot \mathcal{F}\right) \cdot \mathcal{F}
$$
- 尺度注意力:1×1卷积,强sigmoid激活函数
$$
\pi_{L}(\mathcal{F}) \cdot \mathcal{F}=\sigma\left(f\left(\frac{1}{S C} \sum_{S, C} \mathcal{F}\right)\right) \cdot \mathcal{F}
$$
- 空间注意力:首先使用可变性卷积稀疏地学习注意力,然后在相同的空间位置聚合不同层次的特征,K是空间系数采样点,delta_pk是学习到的位置偏移,delta_pk关注差异区域,delta_mk是学习pk位置的尺度变化
$$
\pi_{S}(\mathcal{F}) \cdot \mathcal{F}=\frac{1}{L} \sum_{l=1}^{L} \sum_{k=1}^{K} w_{l, k} \cdot \mathcal{F}\left(l ; p_{k}+\Delta p_{k} ; c\right) \cdot \Delta m_{k}
$$
- 任务注意力:动态切换feature的通道来满足不同的任务。alpha、beta学习激活阈值。theta()函数首先使用GAP降低维度,然后使用两层FC和一个norm层,最后使用一个偏移的sigmoid函数将输出映射到[-1,1].
$$
\pi_{C}(\mathcal{F}) \cdot \mathcal{F}=\max \left(\alpha^{1}(\mathcal{F}) \cdot \mathcal{F}{c}+\beta^{1}(\mathcal{F}), \alpha^{2}(\mathcal{F}) \cdot \mathcal{F}{c}+\beta^{2}(\mathcal{F})\right)
$$

多此使用dynamic head block进行增强。
从图1可以看出,最初backbone输出的是充满噪声的,通过各个模块都显示了较好的注意力性能。
如何集成到其他目标检测方法中
- 单阶段
- 双阶段
和其他注意力机制的关系
-
可变性卷积:可变性卷积通过稀疏采样极大地提升了传统卷积的变换学习能力,虽然它很少用在head中,但是可以把它看作是在S维度上的一个单独的建模
-
非局部:非局部网络[30]是利用注意力模块来提高目标检测性能的先驱,但它采用了一种简单的点积公式,通过融合来自不同空间位置的其他像素的特征来增强像素的特征。这种行为可以被视为只对表示中的L×S子维度进行建模
-
transformer:Transformer提供了一个简单的解决方案,通过应用多头全连接层,从不同的模式学习交叉注意力和融合特征。在我们的表示中,这种行为可以被视为只对S × C子维度建模。
实验
实验设置(略)
消融实验

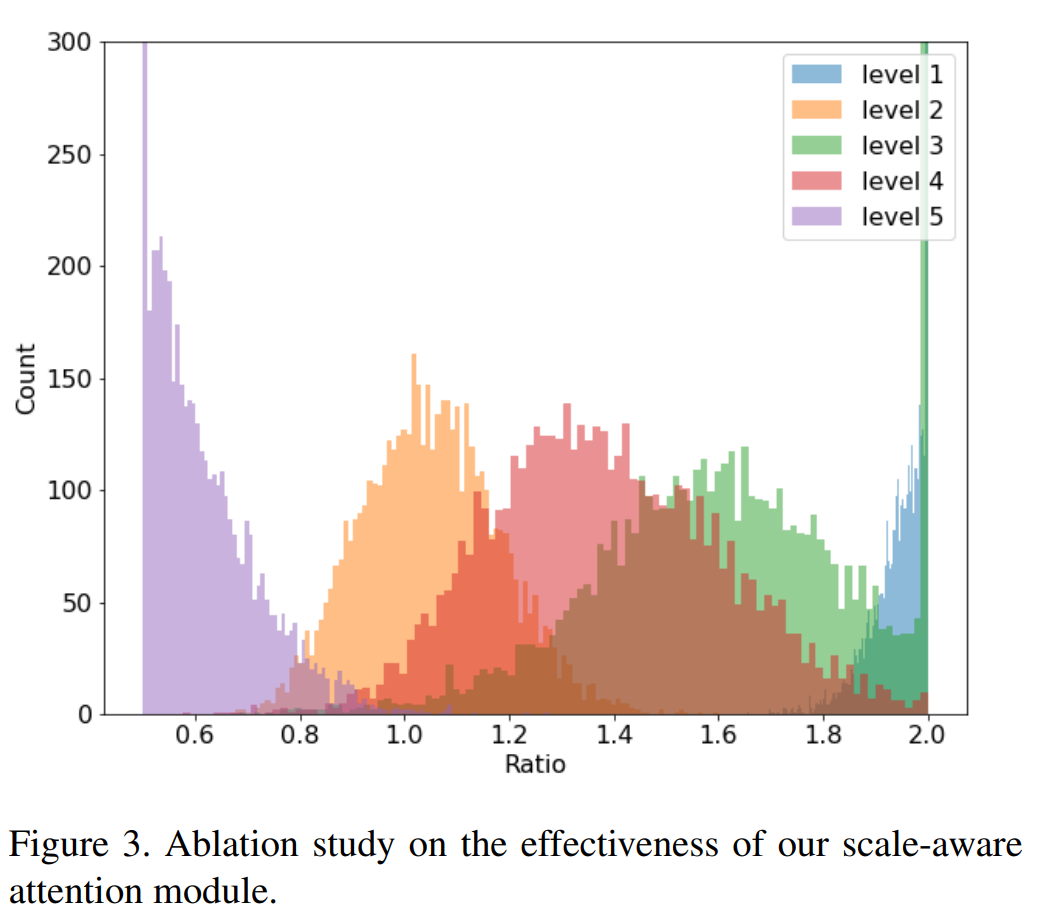
高分辨率特征图(level5)变到低分辨率
低分辨率特征图(level1)变到高分辨率
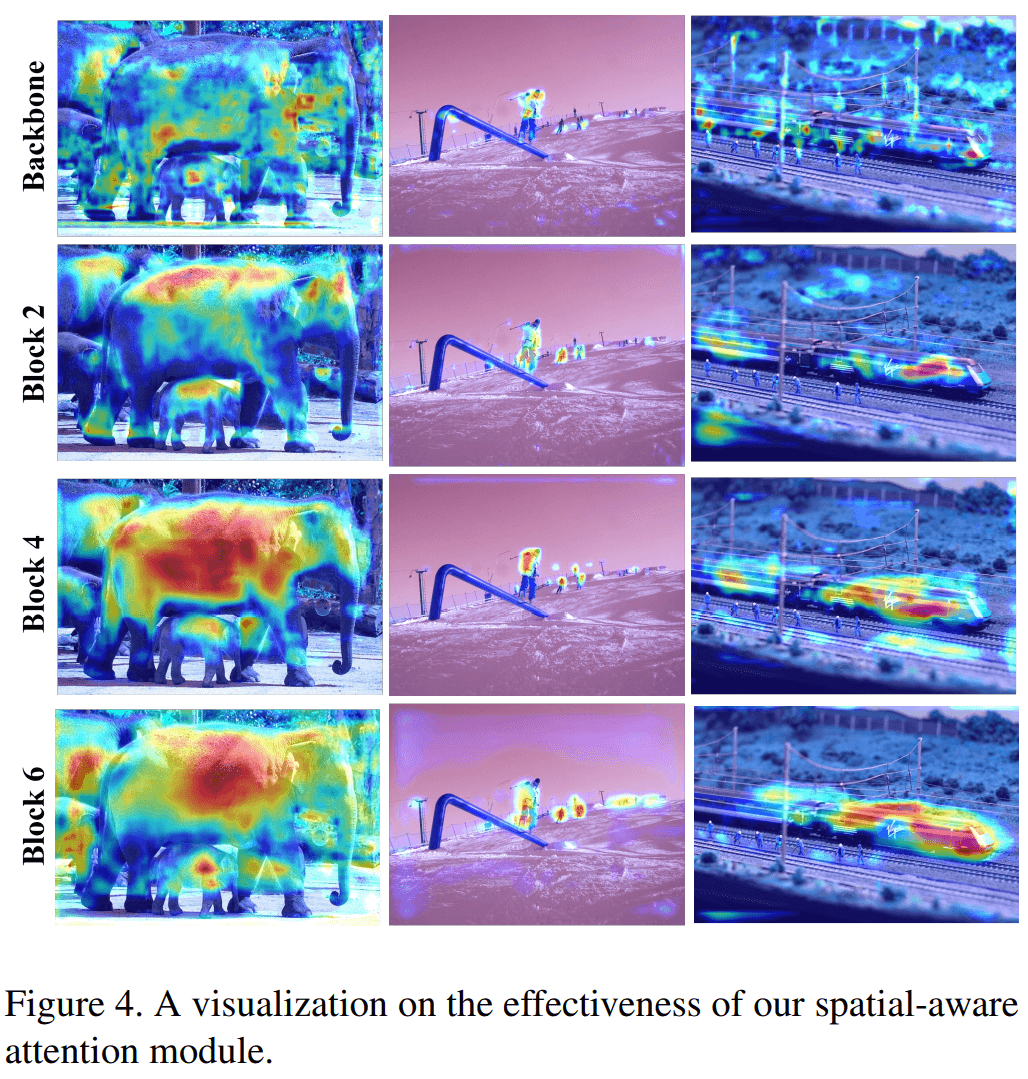
进入和输出的特征图的对比

