应对雷达信息的稀疏性
雷达点云数据具有稀疏性,而图像数据是密集的,这使得融合难以有效进行。先前的学者通过柱扩张的方式强行使得雷达数据更加稠密,这虽然有一定的效果,但是还是难以起到很好的说服力。
柱扩张及其变式
这类方法主要针对点云数据,他们都认为点云代表了目标的位置,用柱体扩张来代表目标的体积,然后投影到像平面上进行进一步的融合。这里面有**“以点代面”**的思想
2019 - Felix - CRF-Net
这种方法是比较原始的,最早还是Felix于19年使用,他的问题主要在于:
-
对于不同类型的目标,柱体的大小应该不一样
-
点云未必刚好在目标的中心,投影之后就存在偏差,甚至未必对应目标(其实是配准问题)
2021 - Nabati - CenterFusion
在WACV2021中,Nabati巧妙地将检测框和柱体扩张通过视锥关联机制整合到一起,不再是简单地投影柱体,而是将检测框缩比,解决了上面两个问题。

改变雷达数据形式
改变雷达数据的形式,用频率图、时频图等形式。受数据集的限制,(2019-2020年主要还是基于nuScene和KITTI,他们两个都是只有雷达点云数据)直到2021年具有更底层雷达数据形式的数据集才陆续出现,以下两者都自己采集了数据集。
2021 - Wang Yizhou - RODNet
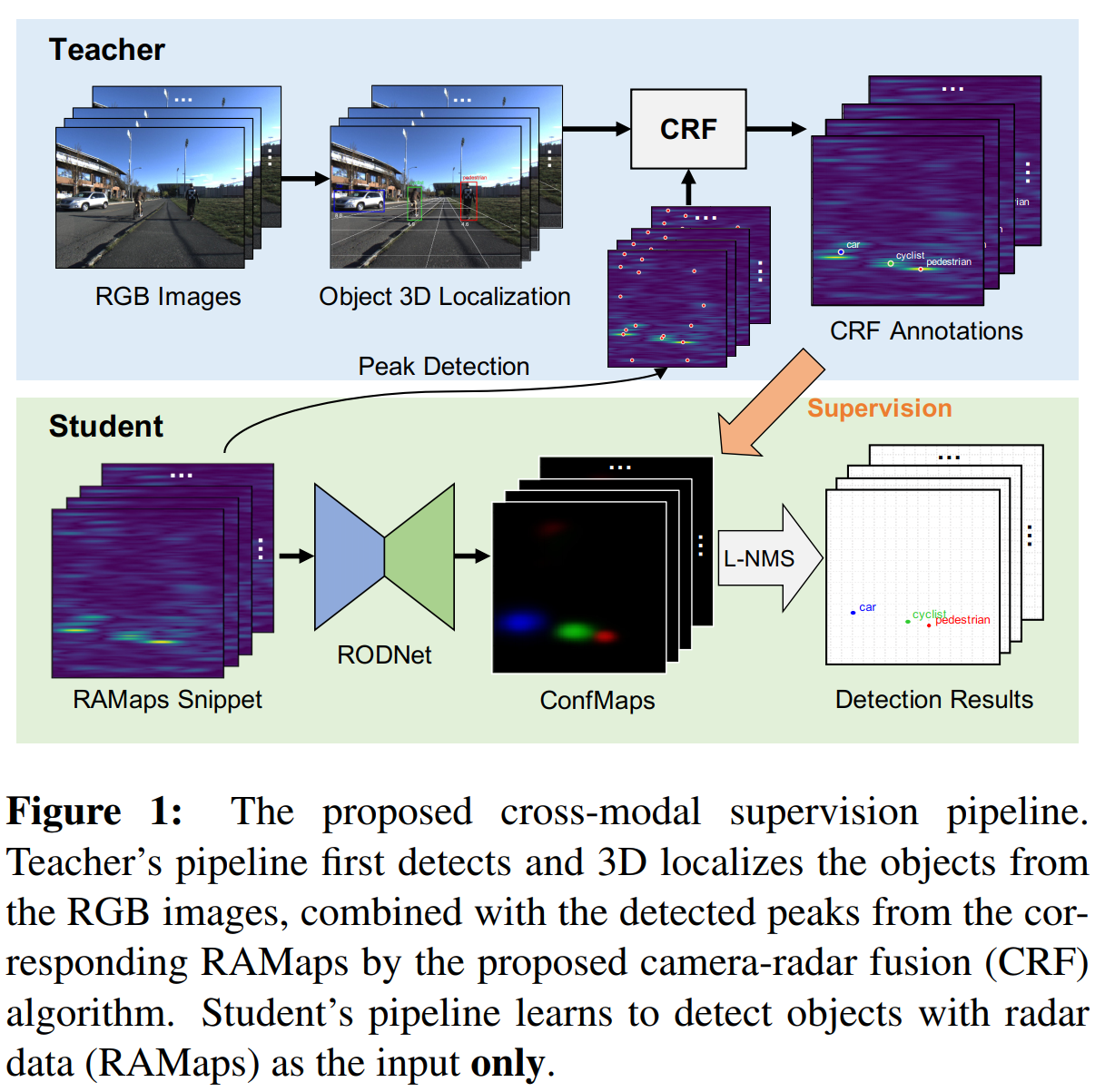
-
使用了雷达频率图RF
-
RAMaps(range-azimuth heatmaps)的性质:
- 可以被解释为在BEV下,x轴为角度,y轴为距离
- 雷达回波信号→FFT→LPF(low-pass filter),然后从另外一个接收天线也进行FFT从而估计角度,最后得到RAMaps
-
RF data的性质:
-
丰富的运动信息。为了利用这个运动信息,需要考虑多个连续的雷达帧作为输入
-
不一致的分辨率:距离分辨率高,角度分辨率低
-
不同的表示形式
-
2021 - Wang Zhangjing - RCF-Fast RCNN
使用具有微多普勒特征的雷达时频图像。
微动与微多普勒特征:通常定义微动(Micro.Motion)为除质心匀速以外目标的微小运动,这种定义忽略 了径向加速带来的影响。目标的径向机动也会使信号频谱展宽,所以除了是质心作匀速 运动以外的运动,如振动、自转,旋动,翻滚、加速运动等都可以称为微动。从多普勒效应上来看,目标的微动会在频谱上引起额外的调制,出现旁瓣或者频谱展宽等,这种现象就称为微多普勒效应

挖掘雷达数据的时序信息
挖掘雷达的时序信息是一个目前还关注十分少的点,这种方法具有一定的合理性,原因在于
- 传统的雷达识别方法,例如RCS法就需要时序雷达信号信息
- 考虑到时序性之后,有助于缓解雷达信号的稀疏性
- 考虑时序信息之后,随着时间的增加,对判断的结果的置信度也能不断提升
2021 - Felix - KPConv-CLSTM
Felix最先注意到了相关内容,但是受限于只有点云雷达数据,他利用核点卷积层(Kernel Point Convolution ,KPConv )来提升特征提取效果。 他使用了LSTM长短时记忆神经网络来学习时序雷达信号的特征。
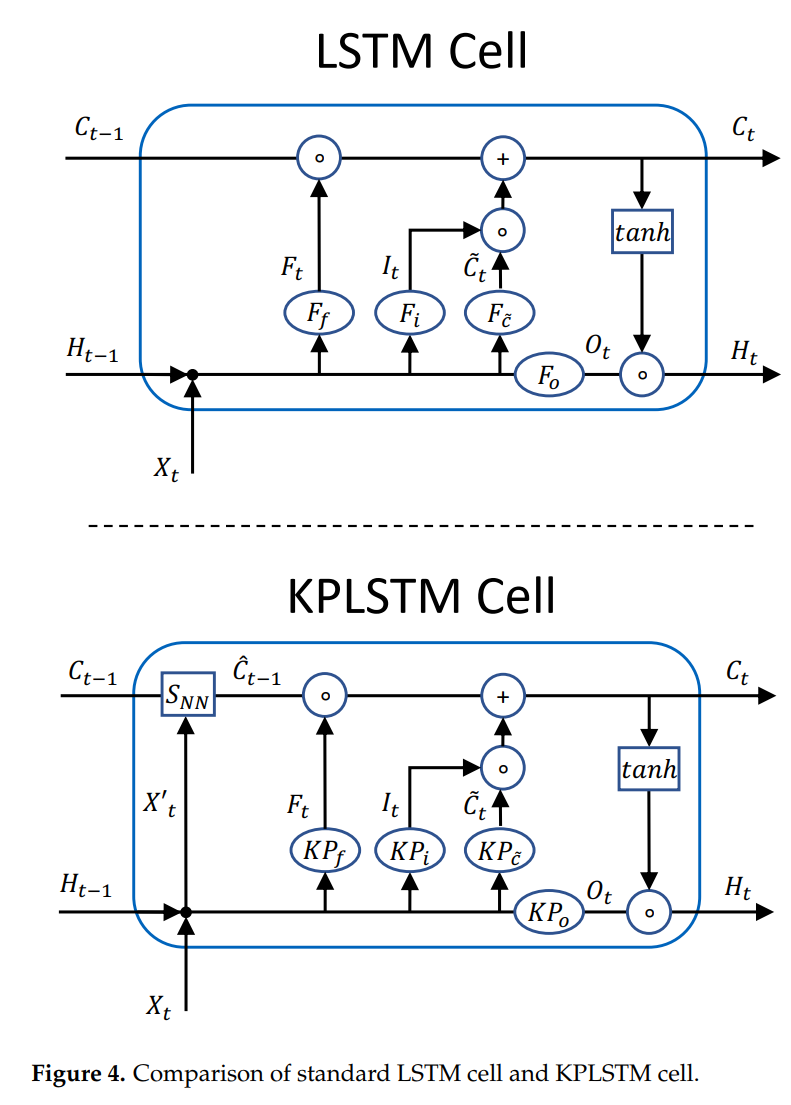
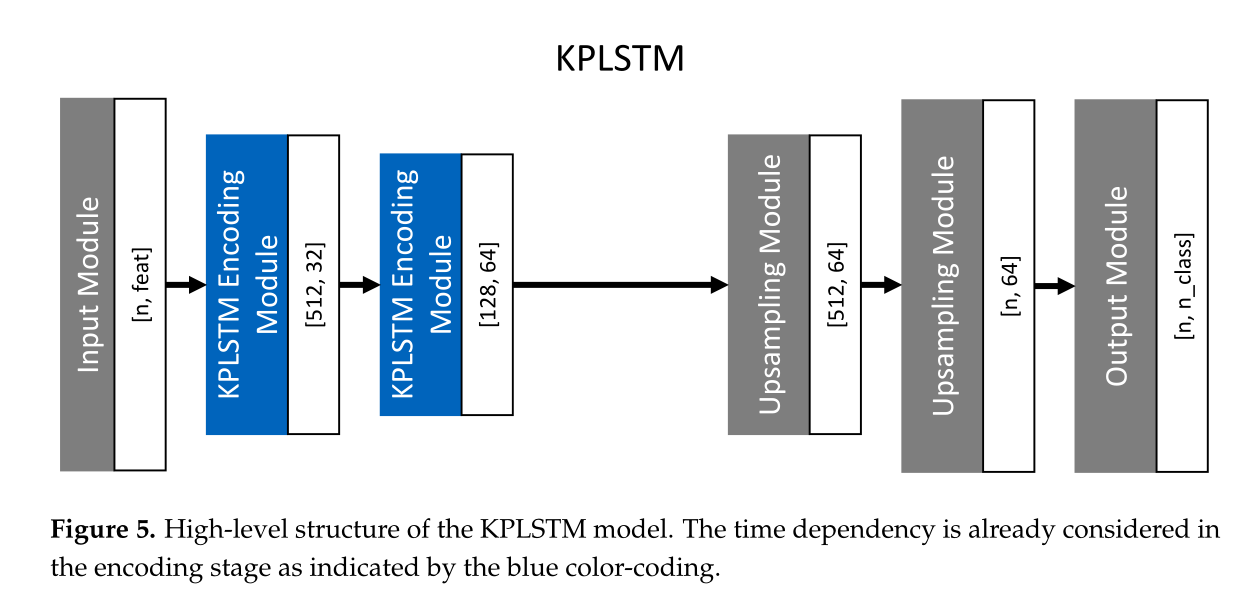
雷达-相机信息数据配准
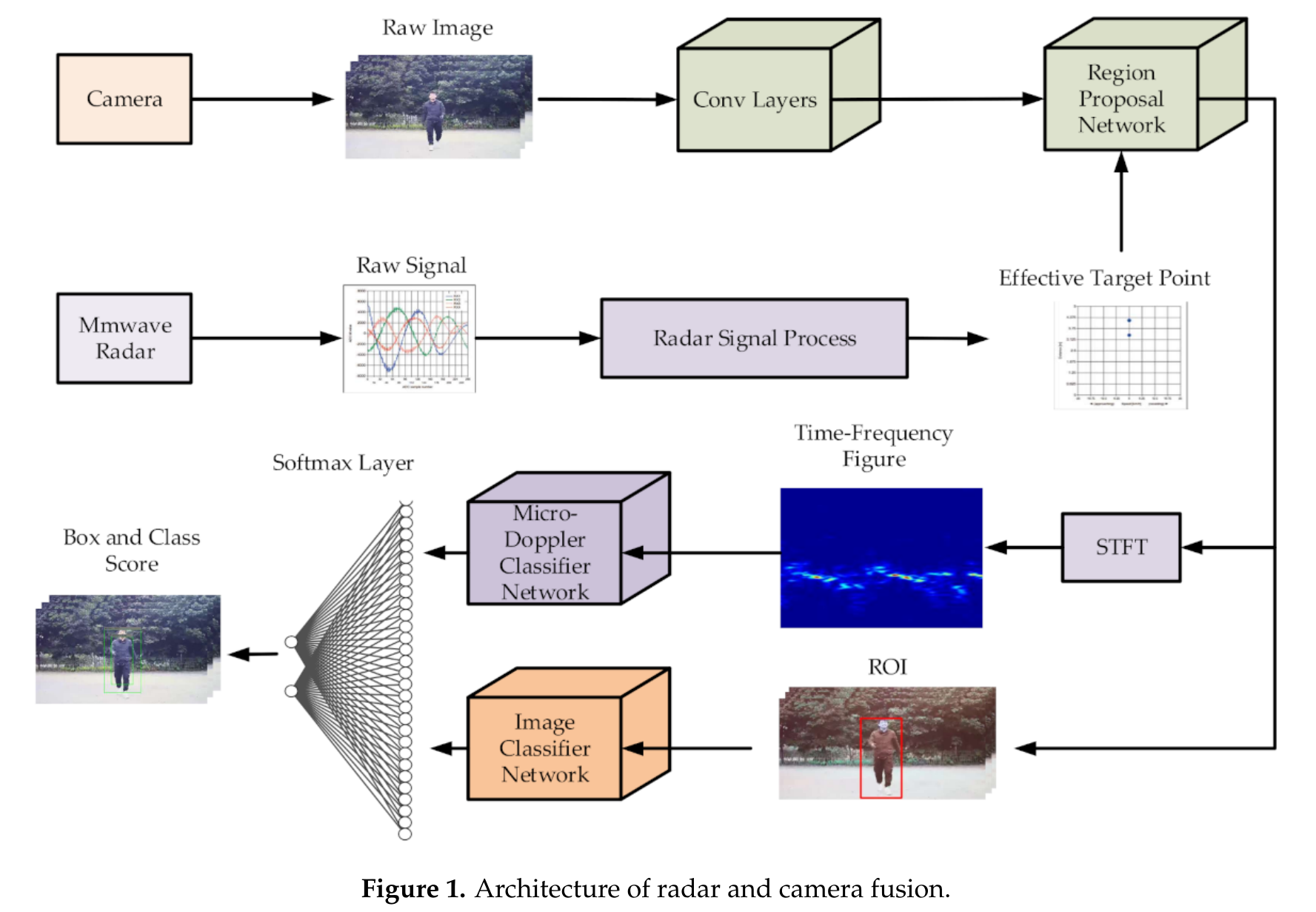
2019年,Felix提出了经典的融合方法,将雷达数据点进行了投影,对两种数据都分别通过多层VGG16网络提取特征之后,让雷达和图像数据自动学习出融合的深度是多少,然后进行concate,但是最终的效果却并不是很好。
之后的学者发现提升融合精度的主要关键在于:数据配准。即:针对同一个目标,需要将有效的雷达数据和图像检测框进行关联
这个问题的难点主要在于:
-
雷达检测和图片检测很可能不是一对一映射的;很多场景中的目标会产生很多个雷达检测,并且也有些雷达检测根本不对应任何目标。
-
雷达的z方向并不准确,甚至根本不存在:由于雷达的z方向不是十分准确(甚至根本不存在),映射后的雷达检测可能会超出相应目标的2D检测框。
-
被阻挡的物体如何关联?(有雷达点, 无检测框):被阻挡的物体会映射到图片的相同区域,这使得在2D图像上区分他们十分困难,几乎不可能。
其实,从逻辑上来讲,雷达和相机都只能得到目标的某些特征,配准更像是用
视锥关联机制
2021 - Nabati - CenterFusion
基于表征学习的关联方法
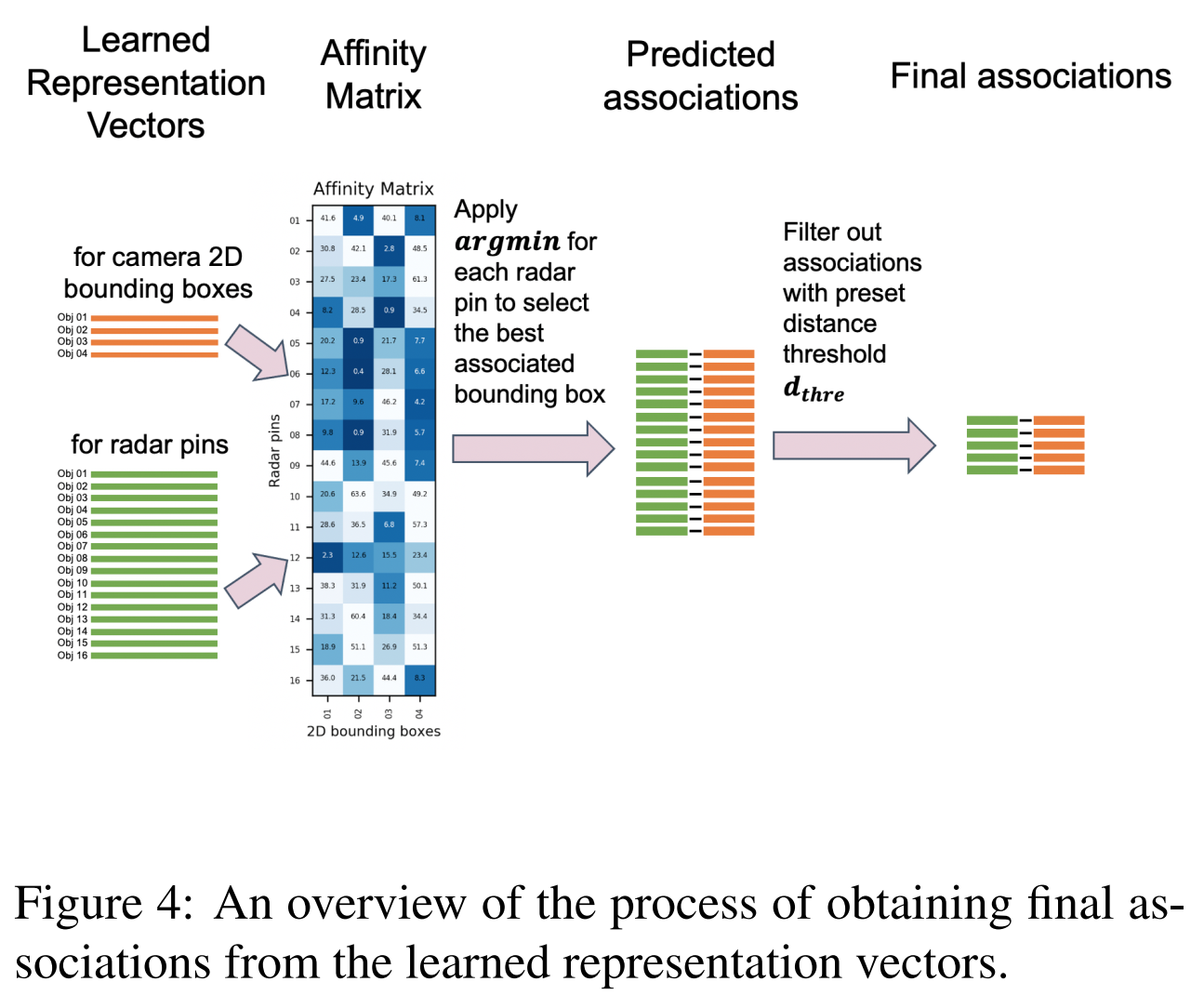
2021 - Xu Dong - RCF-Representation learning
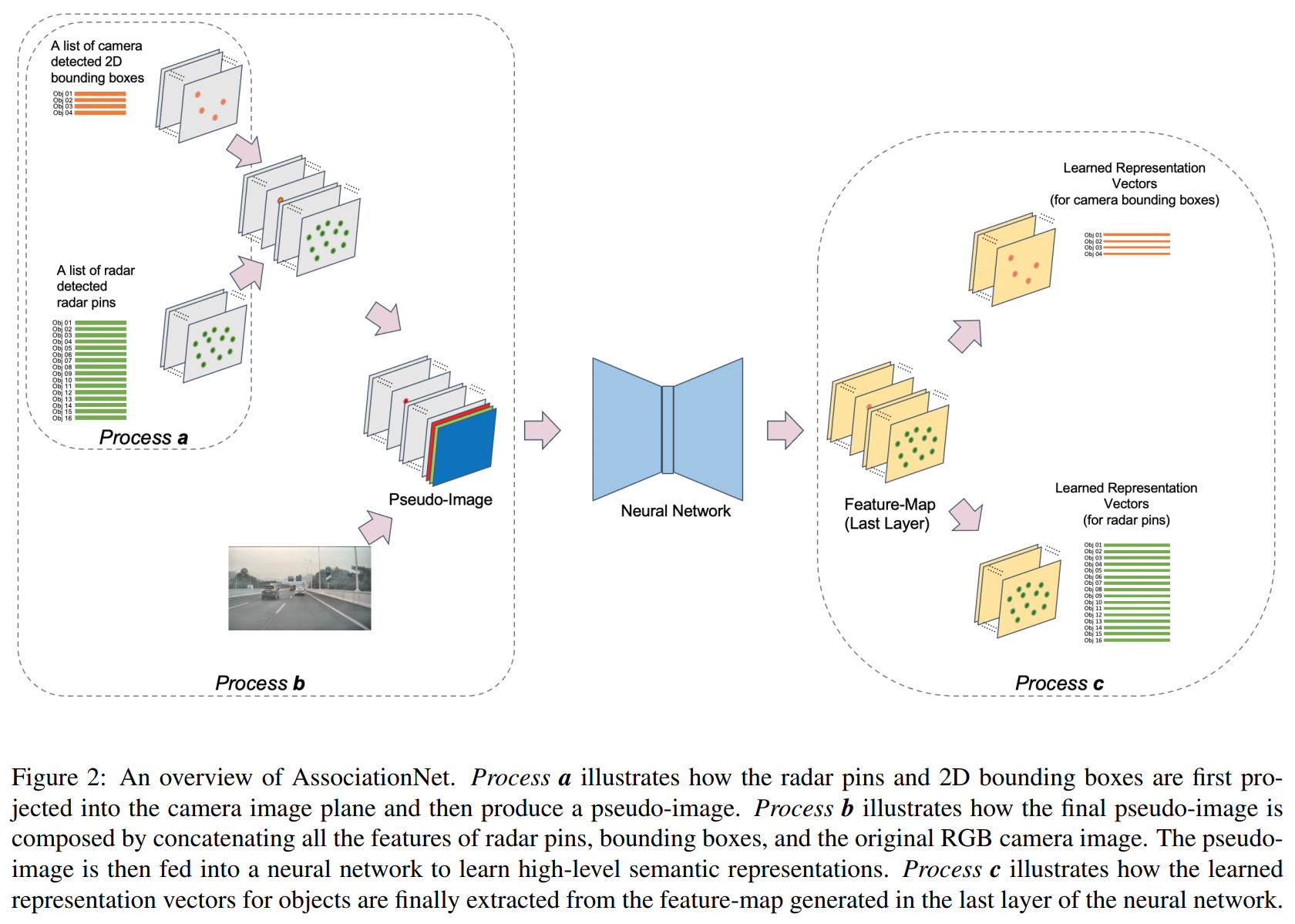
AssociationNet原理:利用AssociationNet学习每个雷达针和每个检测框的语义表征信息。在这个表征下,一对匹配的雷达针和检测框将会”看上去“相似,即他们的学习表征距离比较接近。
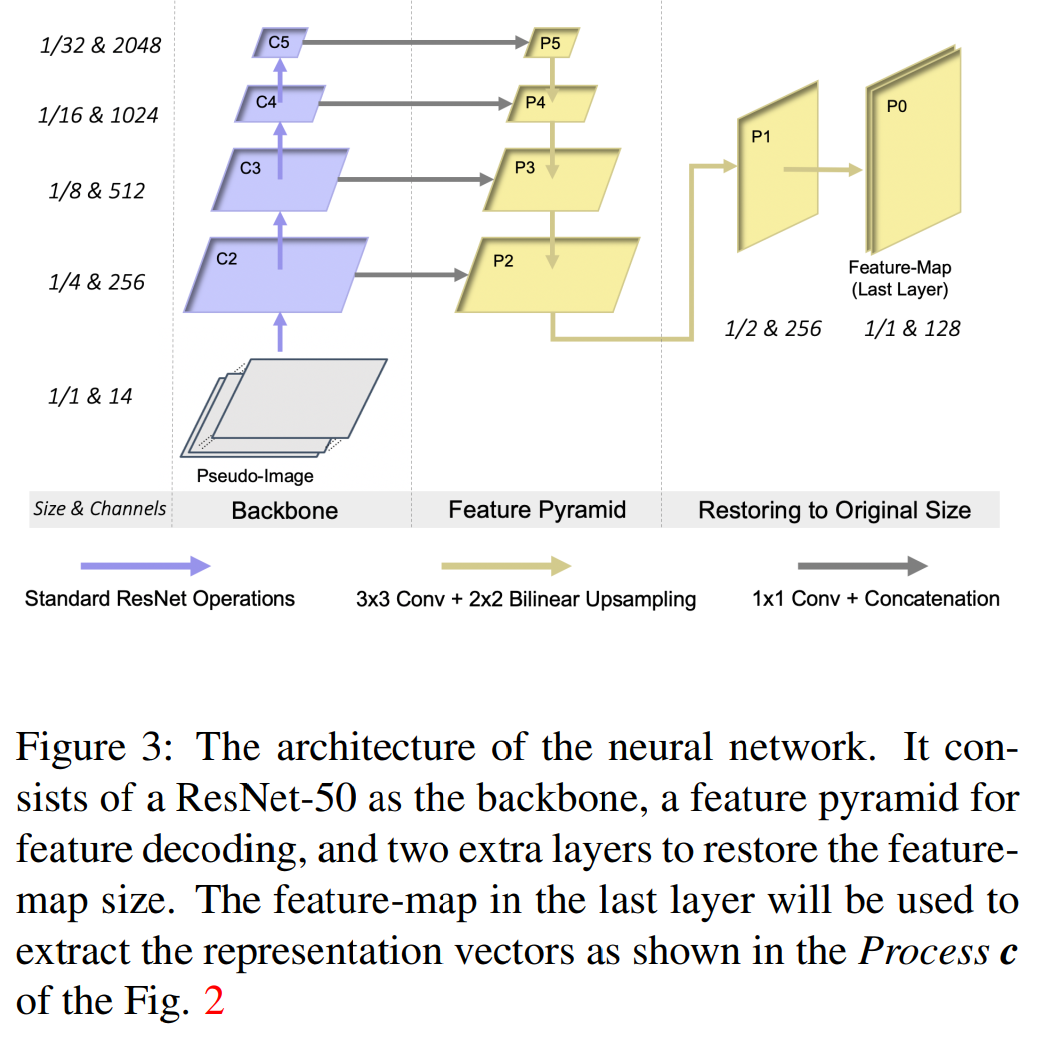
- Backbone:ResNet
- FPN:融合不同尺度的特征
- two extra layers :将特征恢复到输入图的尺寸
输出的特征图包括了雷达针和检测框的高维语义表征信息。每个雷达针和检测框都在特征图中有独有的像素位置,我们在输出的特征图的对应像素位置提取他们的表征向量。这个过程就是process c。
-
推理使用过程