
sensor fusion
这篇主要还是总结了一下关于异类融合的方法、算法。
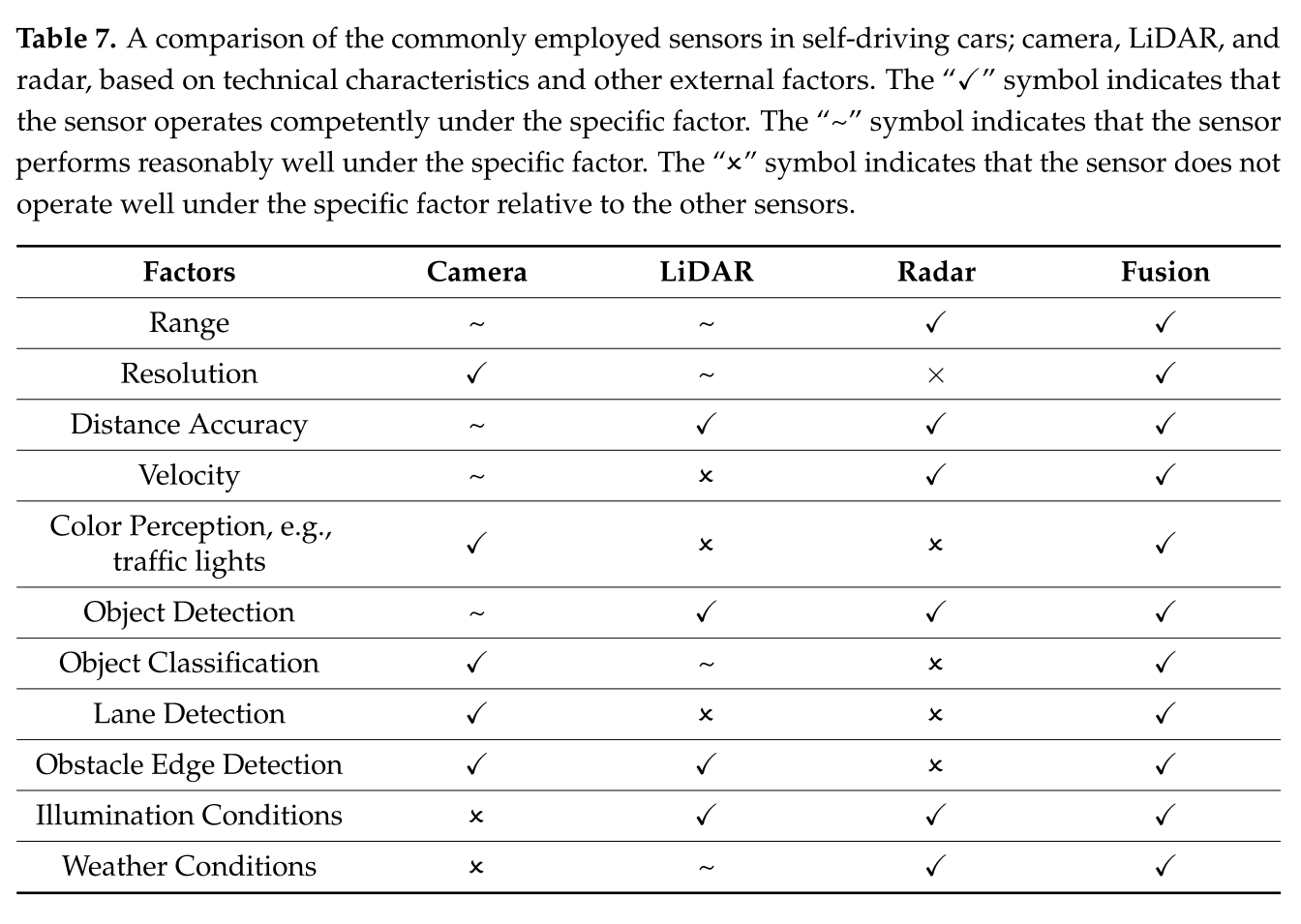
相机、激光雷达、雷达传感器的特点对比
这张表清晰地给出了他们的优劣势,有力地回答了一个问题:我们为什么要研究异类信息融合?
说白了就是:取长补短,得到总体更好的感知效果。
三种主要的传感器融合
- CL (camera-LiDAR)
- CR (camera-radar):CR是目前应用最广泛的,CLR次之,然后是CL.[21];Tesla还利用CR和其他传感器例如超声波传感器融合来得到车辆的环境。[8]
- CLR (camera-LiDAR-radar):通过激光雷达得到精度更高,范围更大的结果。Waymo and Navya[179]等人就利用了这种融合
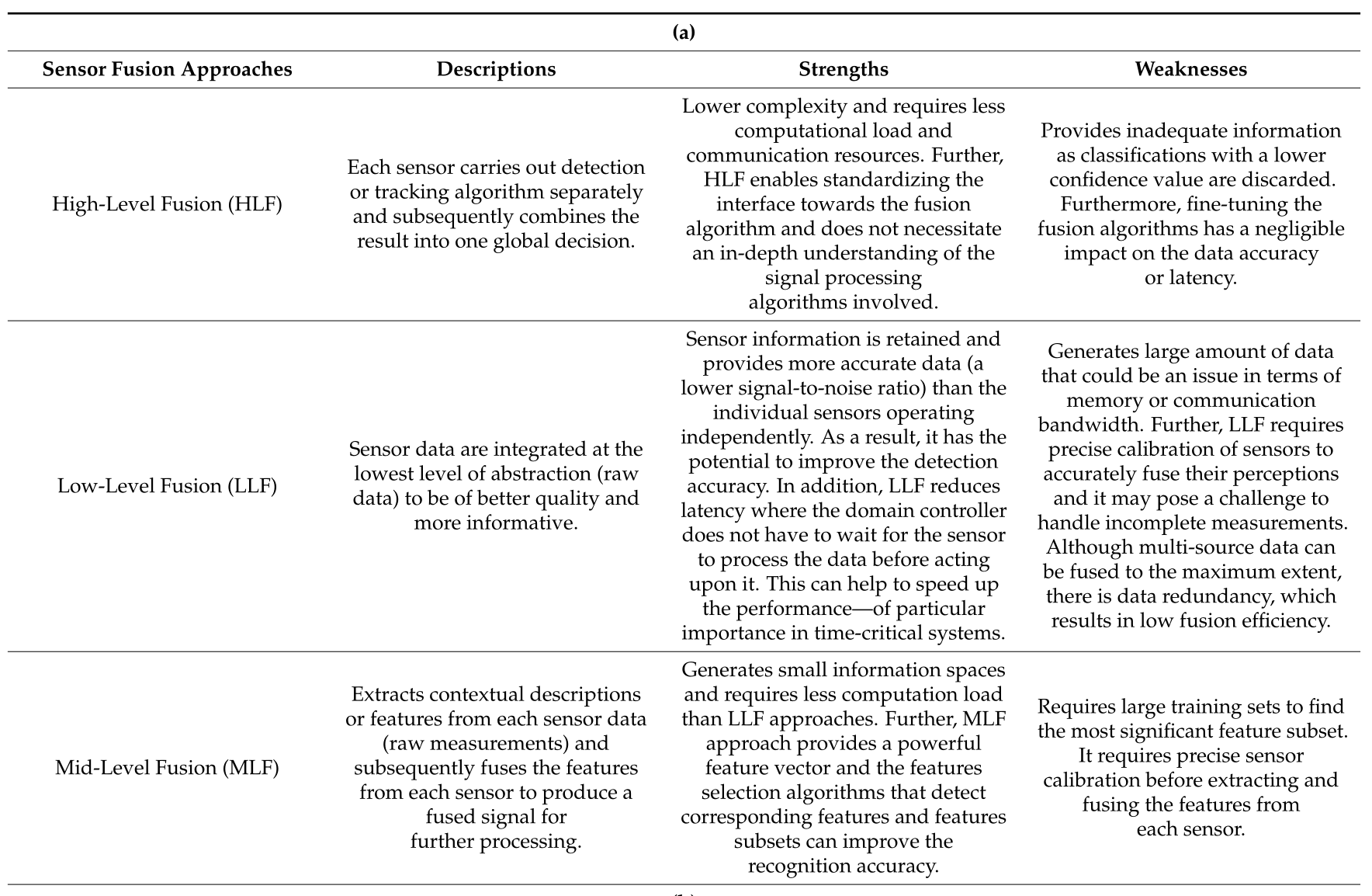
传感器融合的方法对比
目前还是按照融合框架分为三种:
HLF (high-level fusion)
在HLF方法中,每个传感器独立进行目标检测或跟踪算法,然后进行融合。
例子:参考文献[30]利用HLF方法将处理后的数据,即雷达信号与激光雷达点云独立融合,然后使用非线性卡尔曼滤波方法检测障碍物和状态跟踪。
通常采用HLF方法是因为相对的复杂度比LLF和MLF方法要低。然而,HLF提供的信息不充分,例如,如果存在若干重叠障碍,则丢弃具有较低置信值的分类。
LLF (low-level fusion)
相反,在LLF方法中,来自每个传感器的数据在最低抽象级别(原始数据)进行融合。因此,所有的信息都被保留下来,可以潜在地提高障碍物检测的准确性。
例子:文献[181]提出了一种两阶段的3D障碍物检测体系结构,命名为3D-cross view fusion(3D- CVF)。在第二阶段,他们利用LLF方法,利用基于3D感兴趣区域(RoI)的池化方法(3D region of interest(ROI)-based pooling),将第一阶段获得的相机-激光雷达联合特征图(camera-LiDAR joint feature map)与低级相机和激光雷达特征(low-level camera and LiDAR feature)融合。他们在KITTI和nuScenes数据集上评估了所提出的方法,并报告称,物体检测结果优于KITTI排行榜上最先进的3D物体检测器(更全面的总结见参考文献[181])。
在实践中,LLF方法带来了许多挑战,尤其是在其实现方面。它需要精确的外部校准传感器,以准确地融合其对环境的感知。传感器还必须补偿自我运动,并进行时间校准[180]。
MLF (middle-level fusion)
MLF,也称为特征级融合,是LLF和HLF之间的一个抽象级别。它将从相应的传感器数据(原始测量值)中提取的多目标特征进行融合,如图像中的颜色信息或雷达和激光雷达的位置特征,然后对融合后的多传感器特征进行识别和分类。
例子:文献[182]提出了一种特征级传感器融合框架,用于在通信能力有限的动态背景环境中检测目标。他们利用符号动态滤波(Symbolic Dynamic Filtering, SDF)算法,在环境光强变化的情况下,从多个红外传感器中提取不同方向的低维特征,然后将提取的特征与运动目标的凝聚层次聚类算法融合成簇检测。
然而,由于MLF对环境的感知有限并丢失了上下文信息,似乎不足以实现SAE 4级或5级的自动驾驶系统[183]。
下表清晰地展示了各种融合方法的描述和优劣势:
融合算法(工具)
上一部分讲解的是一些抽象的融合架构,这一部分更加关注于具体的算法,或者说:工具。这些经典的目标检测和分类算法可以作为我们的网络的主干结构。下面介绍几种常用的。
YOLO
用于二维图片目标检测
You only look once(YOLO)在2016年被提出,成为了目标检测算法的一个重要的里程碑事件[188]。
例子:文献[187]提出了一种先进的加权平均YOLO算法来融合RGB相机和激光雷达点云数据,以提高目标检测的实时性能。
文献[190]中,作者提出了一种基于cnn的方法,利用近红外光和热感摄像机通过情绪来检测攻击性驾驶行为。他们利用CNN输出的近红外光图像和热图像的分数进行分数级融合,以提高检测精度。他们提出的方法获得了较高的情绪分类精度,并证明了他们提出的技术比传统的情绪检测方法取得了更好的性能。
VoxelNet
用于三维目标检测,处理3D点云数据
文献[191]VoxelFusion: 利用了他们之前在[192]中提出的VoxelNet框架,提出了两种特征级融合方法,即PointFusion和VoxelFusion,将RGB和点云数据结合起来进行3D对象检测。VoxelFusion方法将VoxelNet创建的非空3D体素投影到图像上,并在2D的ROI区域中提取特征,从而在像素水平上能和之前的图像特征进行叠加(concatenate)融合
文献[193]PointFusion: 提出了一个点融合框架,利用图像数据和原始点云数据进行3D对象检测。他们利用CNN和PointNet[194]架构分别对图像和点云进行处理,然后将结果输出组合起来以预测多个3D检测框的假设位置及其置信度。PointNet体系结构是一种新颖的神经网络,为处理原始点云数据的3D分类和场景语义解析等应用提供了统一的体系结构。
其他基于深度学习的传感器融合算法包括:
- [195]:ResNet,或残差网络,是一种残差学习框架,有助于深度网络的训练。
- [196]:SSD (Single-Shot Multibox Detector)是一种将包围盒离散为一组不同尺寸和长宽比的盒子,以检测不同尺寸的物体的方法[196],它克服了YOLO小尺度和变化尺度的物体检测精度的限制
- [197]:CenterNet代表了最先进的单目摄像机三维物体检测算法,该算法利用关键点估计来找到包围盒的中心点,并将中心点回归到所有其他物体属性,包括尺寸、3D位置、方向和姿态。

