
论文笔记,原创内容;未经许可,请勿转载
Abstract
- 背景:雷达和图像是成熟,低成本,鲁棒并且广泛应用在产品级的感知手段,由于他们的互补性,雷达检测(点云)和图像(2D检测框)通常被融合后生成最优感知结果。雷达-图像融合成功的关键点是数据关联。
- 工作:我们想通过深度表征学习(deep representation learning)进行rad-cam关联,来进行特征级的交互和全局的推理。
- 设计了一种损失采样机理和新型序数损失(ordinal loss )来克服 标签不准确 和强化严格的人类推理(enforce critical human reasoning)
- 结果:
- 尽管在使用具有噪声的标签进行训练的情况下,我们提出的方法实现了92.2% 的F1分数,这比基于规则的老师算法提升了11.6%。
- 除此之外,这种基于数据的方法同样使得其通过极端情况(corner case)挖掘实现不断的性能提升。
Introduction
P1-2: Lidar的缺点&radar的优点
LiDAR的缺点:
- 容易出现错误
- 购买,维护成本高
- 商品级雷达尚未满足需求
毫米波radar的优点:
- 距离速度估计相对精确
- 鲁棒性高,低成本,维护成本低
P3:传统radar融合
传统的radar-carmera fusion:
-
基于关联规则的算法和基于运动学模型的跟踪,关键点是将雷达观测和相机观测进行配准
-
缺点:传统的关联过程是基于最小化特定的距离度量和一些启发式规则“手动”操作的。它不仅需要大量的工程和调优,而且很难适应不断增长的数据。
[16,25,28]: 结合雷达和相机数据作为输入进行3D目标检测,这些方法都以激光雷达数据作为真值来建立radar和相机的关系。对于大部分公开数据集例如nuScenes,Waymo这是足够的,但是 他们不能被部署到大部分商用车辆上。
在这项研究中,我们提出了一个基于可扩展学习的框架来关联雷达和相机信息。
P4:我们的方法
我们的目标:找到雷达和相机检测结果的一个表征形式,能使得配对后的距离近而未配对的距离远。我们将检测结果转换到图像通道上然后叠加到原图上,再进入名为AssociationNet的CNN网络中。训练是通过从基于传统的基于规则的关联方法(rule-based association method)获得的不完美的标签上进行的。通过引入损失采样机制可以减少错误标签。为了进一步提升性能,我们通过增加了一个新型的序列损失(ordinal loss)。该网络通过对于实际场景的推理,显著地超越了基于规则的方法。
P5:我们的主要贡献
- 我们提出了一种可扩展的、基于学习的雷达-相机融合框架,无需使用激光雷达的地面真实标签,适合在真实的自动驾驶应用中构建低成本、可生产的感知系统。
- 我们设计了一个损耗采样机制来减轻标签噪声的影响,并发明了一个顺序损耗来加强关键关联逻辑到模型中以提高性能。
- 我们通过表征学习发展了一种鲁棒性的模型,可以操作多种具有挑战性的场景,,同时它的F1分数比传统的基于规则的算法提升了约11.6%
Related Work
2.1 Sensor Fusion
-
[9,17,19,12,31]: 目标级融合(object-level fusion),各个传感器分别处理数据检测目标,然后融合算法融合目标检测结果形成全局机动跟踪航迹。
-
[1,5]: 3D目标检测和多目标跟踪
传统的方法倾向于手动设计各种距离指标,来表示不同传感器输出之间的相似性。
-
[2]距离最小化和其他启发式规则被用来找到关联方式。为了处理复杂性和不确定性,在关联过程中有时也采用概率模型
2.2 Learning-Based Radar-Camera Fusion
- [28,14]: 前期融合
- [16,7,26]:中期融合
由于从检测结果得到的信息太少,基于融合的目标级融合仍待探索。在本研究中,我们提出的方法属于这一类:我们聚焦于关联雷达和相机的检测结果。因此,我们的方法和传统的传感器融合流程更加兼容。另外一方面,我们的方法直接采用原始相机和雷达数据来进行性能提升增强。
2.3 CNN for Heterogeneous Data
CNN在结构化图片上的巨大成功激发了人们将其应用在其他多种类型的数据上,例如传感器参数、点云和两类数据的关联关系上。为了能和CNN进行兼容,一种流行的方法是将异类数据转化为“伪图片”的形式。例子包括
-
[11]: 用归一化坐标和视场映射将摄像机内在编码到图像中(? ? ?)
-
[6,28]: 将雷达数据投影到图像平面,形成新的图像通道
-
[30,23]:各种形式的基于投影的激光雷达点云表示
我们采用了相似的方法处理雷达和相机输出。
2.4 Representation Learning
表征学习被认为是理解复杂环境和问题的关键[3,20,18]。表征学习被广泛应用于许多自然语言处理任务,如单词嵌入[24],以及许多计算机视觉任务,如图像分类[8],目标检测[13],关键点匹配[10]。在本研究中,我们的目标是在高维特征空间中学习一个向量作为场景中每个对象的表征,以建立对象之间的交互,并进行场景的全局推理。
Problem Formulation
-
传感器:
- 相机:FOV:120度,52度;像素:1828*948;频率:10Hz
-
雷达:输出的是一系列经过后处理的点,这些点据有一些属性,也叫做雷达针(radar pins)。这些雷达针是在目标级上的。每帧输出都可能有几十个雷达针。
-
-
雷达针值得注意的点:
- 在BEV视角下进行2D信息处理。不考虑仰角,因为在纵向上精度很差
- 每一个雷达针都对应了一个移动的目标(例如车、自行车、行人等)或者是某种具有干扰的静态结构(例如交通牌、路灯、桥等)

在这项研究中,我们聚焦于将来自相机的2D识别框和雷达针相关联。在具有精确关联情况下,许多类似3D目标检测和跟踪的任务会变得更加简单。
Methods
我们的工作主要包括:
-
前处理:配准雷达和相机数据
-
基于CNN的表征学习网络 AssociationNet
-
后处理:表征提取和关联
4.1 Radar and Camera Data Preprocessing
前处理:进行时-空配准。(temporal and spatial alignment)
- 时间配准:将和图片帧时间最近的雷达帧相互进行配准。
- 空间配准:利用已知信息将雷达针从雷达坐标进一步转换到相机坐标。雷达针的所有属性将在AssociationNet中使用。
相机的每帧图像都会先进行2D目标检测并输出检测框,检测框的属性见表2。虽然在本研究中,网络使用的是RetinaNet,其实任何2D检测网络都可。经过前处理,一系列时–空配准的雷达针和相机检测框就可以进行接下来的关联了。

4.2 Deep Association by Representation Learning
P1: 表征学习的原理
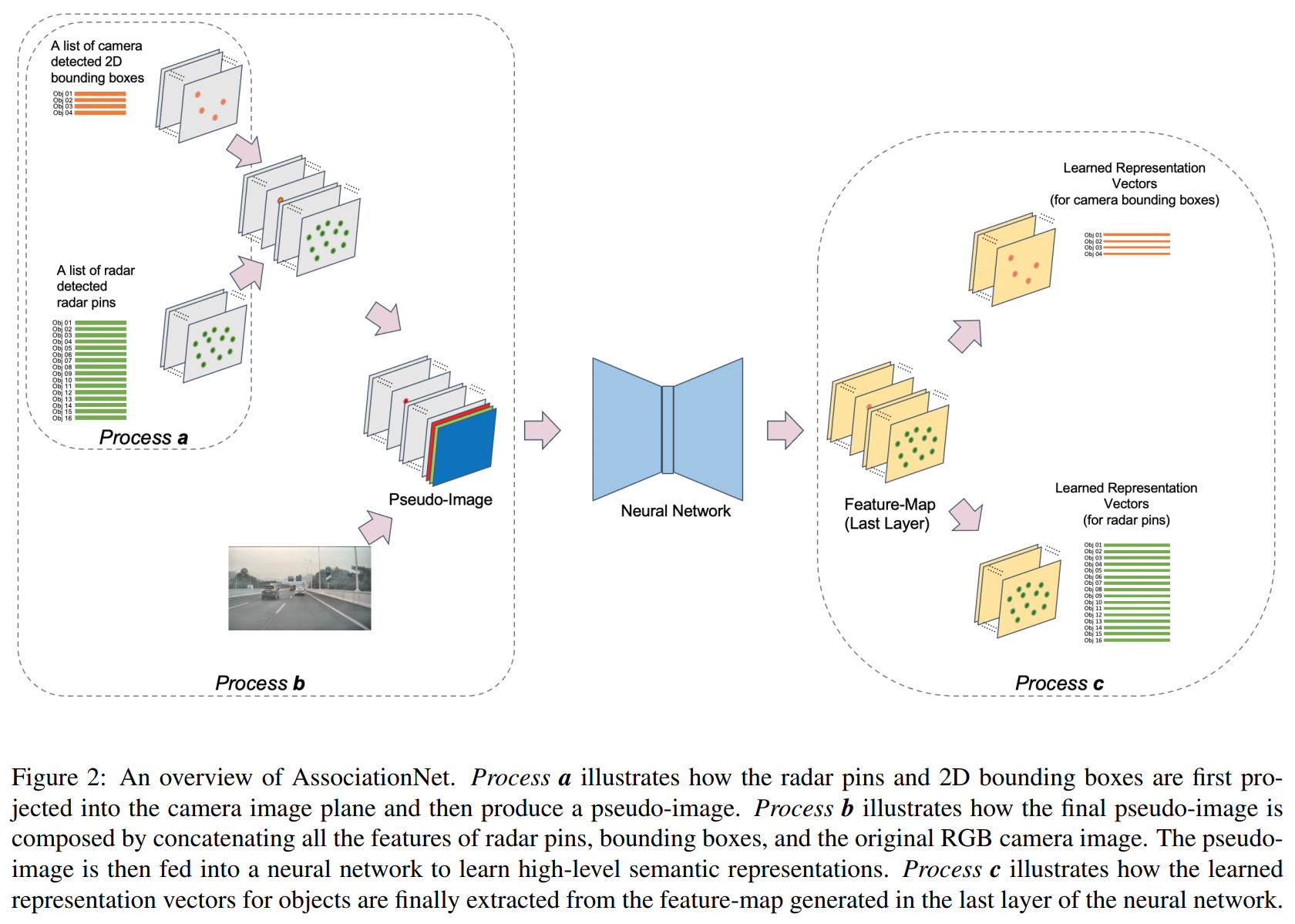
利用AssociationNet学习每个雷达针和每个检测框的语义表征信息。在这个表征下,一对匹配的雷达针和检测框将会”看上去“相似,即他们的学习表征距离比较接近。 这个过程的大致描述见图2.
P2:Process a:得到伪图像;Process b:叠加原图
为了利用强大的CNN架构工具,我们将每个雷达针和2D检测框投影到像平面来产生一个伪图像(pseudo-image),每一种属性都占据了一个独立的通道。
Process a:
- 每一个检测框被分配到其中心的像素位置上
- 每一个雷达针通过将其3D位置投影到相平面上来分类到像素位置上
接下来,我们将原始RGB相机图像和相应的伪图像叠加以合并丰富的像素级信息。然后应用AssociationNet进行表征学习。
P3: AssociationNet的结构;process c:提取表征向量
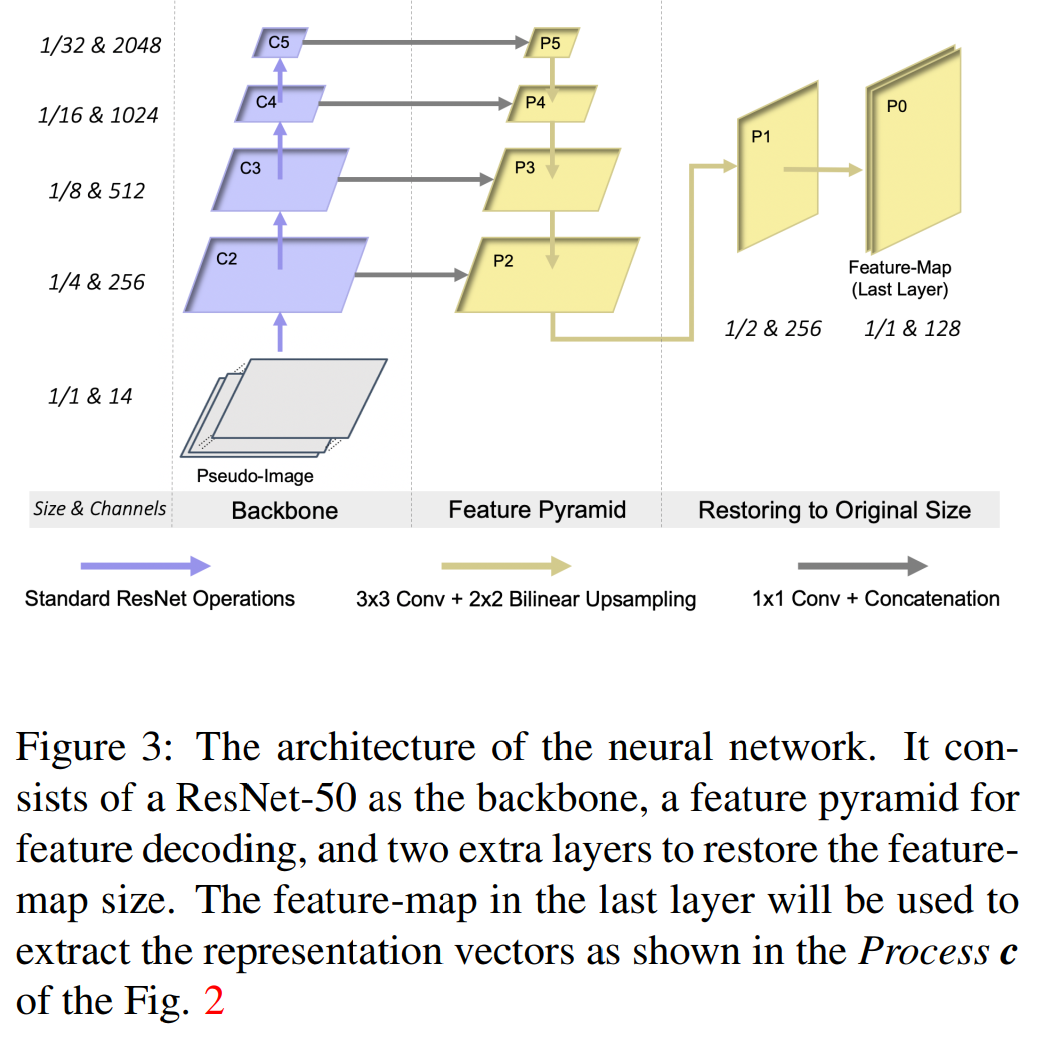
- Backbone:ResNet
- FPN:融合不同尺度的特征
- two extra layers :将特征恢复到输入图的尺寸
输出的特征图包括了雷达针和检测框的高维语义表征信息。每个雷达针和检测框都在特征图中有独有的像素位置,我们在输出的特征图的对应像素位置提取他们的表征向量。这个过程就是process c。
P4: 网络的输入及输出
-
输入-伪图:
- 7个雷达针通道:object-id, obstacle-prob, position-x, position-y, velocity-x,
velocity-y, heatmap - 4个检测框通道:height, width, category, heatmap
- 3个原图RGB通道
- 7个雷达针通道:object-id, obstacle-prob, position-x, position-y, velocity-x,
-
输出-特征图:
- 总共128通道
- 每个雷达针的表征向量 64维
- 每个检测框的表征向量 64维
P5:损失函数
我们所得到的表征向量代表了雷达针和检测框在高维空间中的语义含义。如果一个雷达对表示了现实世界中的同一个目标,我们就把它作为一个正样本,反之为负样本。我们尝试最小化所有的正样本的表征向量之间的距离,并且将负样本的表征向量之间的距离最大化。基于这个逻辑,我们设计了根据关联真值标签的损失函数。我们将这些正样本的表征向量加和到一起,得到吸引损失(pull loss):

我们将负样本的损失加和,得到排斥损失(push loss):

-
POS,NEG:正样本集、负样本集
-
npos,nneg:POS中的关联数和NEG中的关联数
-
(i1,i2):第i个关联对,包含雷达针i1,检测框i2
-
hi1,hi2:代表对应的学习出的表征向量
-
m1,m2:设想的表征向量间的距离的阈值,我们设定为了2.0和8.0
在推理过程中,我们计算了所有可能的雷达针-检测框对的表示向量之间的欧氏距离。如果距离低于一定阈值,则认为雷达针与检测框成功关联。
4.2.1 Loss Sampling
用于监督学习过程的关联标签基本上来自于传统的基于规则的方法,这些标签远远没有达到100%精确度并且包含了部分噪声。
- 训练时:过滤某些关联标签:为了减轻不准确的标签的影响,我们首先通过过滤掉了某些低可信度的关联对,以纯化标签。这提升了剩余关联标签的精确度,但是代价是破坏了回归结果(undermined recall)。
- 训练时:过滤某些排斥标签对在训练AssociationNet 时,排斥损失的计算过程中,我们只取样了一部分用来训练,以减少错误地分开了正关联对。取样的负关联对的数目和正关联对的数目相等。
4.2.2 Ordinal Loss
AssociationNet 犯的一个特殊类型的错误是:它可能会违反简单顺序规则(simple ordinal rule),即这种现象:一个较远的雷达针关联到一个较近的检测框,一个较近的雷达针关联到了较远的检测框。为了解决这个情况,我们提出了顺序损失。
将检测框i的底部的y坐标设为ymax_i,相应的3D世界的深度为d_i。对于任意两个在同一张图片上的检测框,我们有如下的性质:

物体在3D世界中的顺序可以通过检测框底部的相对距离次序来推测。因此,我们设计了一个额外的顺序损失根据顺序规则来强化自身一致性(self-consistency ),这个损失是:

- ^POS:预测的正关联集
- ^n_pos:^POS的大小
- i1,i2:第i个预测关联的雷达针和检测框
- j1,j2:第j个预测关联的雷达针和检测框
- d*:相机坐标系下雷达针的深度
- y*_max:检测框底部的y坐标
- σ:激活函数,用来平滑损失值
最后, 总损失为:

其中w_ord是用来平衡损失的权重系数.
4.3 Training and Inference
- 训练:
- 硬件:2080Ti
- batch size: 48
- 训练方法:SGD,10K次迭代
- 学习率:初始10^-4, 8K次迭代结束时下降10倍,9K次迭代结束时再下降10倍
- 推理:
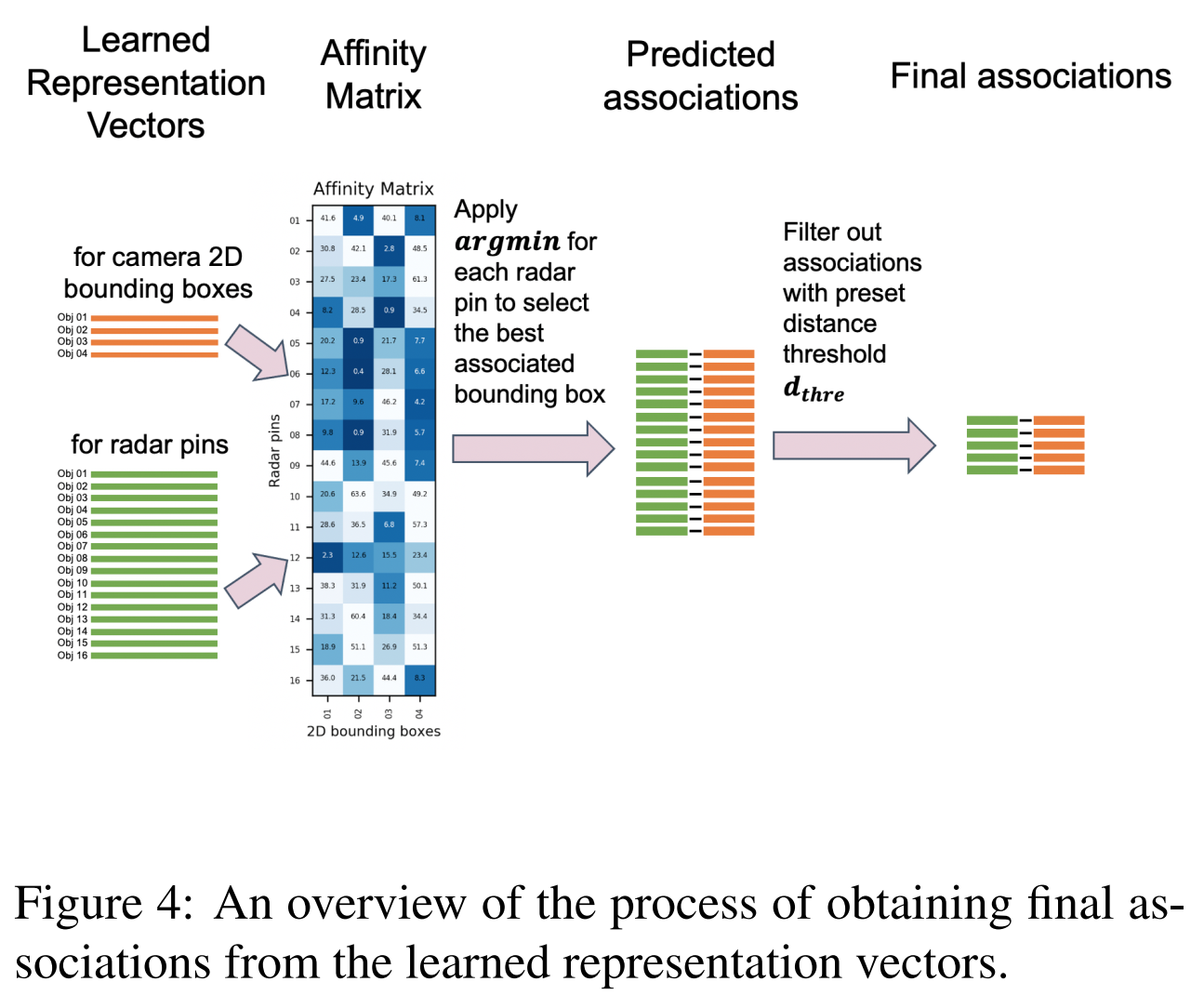
- 首先, 使用训练后的模型先生成雷达针和检测框的表征向量
- 然后计算一个关系矩阵(affinity matrix),其中每个矩阵元素对应于雷达引脚的表示和一个包围框之间的距离。在实际过程中,一个检测框可能和多个雷达针关联,但是每个雷达针只能和最近的检测框关联。因此,我们设计每个雷达针与关系矩阵中距离最小的检测框相关联。
- 最后,距离大于阈值的不可能的关联被过滤掉,这通常包括来自干扰静态物体的雷达针。
- 整个推理过程见图4
4.4 Evaluation
在测试数据集中,将预测的关联与人为标注的关联进行比较。我们使用精度、回忆和F1分数作为评估性能的指标。
在一些非常复杂的场景中,即使是人类的注释员,正确地将所有雷达针和检测框联系起来是非常具有挑战性的。因此,在评估过程中,我们将这些看似可信但不确定的关联标记为“不确定”。示例如图5所示。对于那些“不确定”的关联,它们既不被视为积极的联想,也不被视为消极的联想,这将被排除在正确和错误的正面预测之外。

Experiments and Discussion
5.1 Dataset
AssociationNet在一个内部数据集上进行了训练和评估,该数据集包括由测试车队收集的12个驾驶序列,包括在各种驾驶场景下14.8小时的驾驶,包括高速公路、城市和城市道路。雷达和摄像机最初以10Hz同步,然后进一步降采样到2Hz,以减少相邻帧之间的时间相关性。12个序列中的11个用于训练,另一个用于测试。因此,训练数据集中有同步雷达和摄像机帧数104,314个,测试数据集中有2,714个。对于训练数据,关联标签由传统的基于规则的算法生成,并附加过滤以提高精度。对于测试数据,我们用人工标注来手动整理标签,以获得高质量的ground-truth。
5.2 Effect of Loss Sampling
采样比定义为每帧的正对数与负对数之比。结果如表3所示。我们可以看到,采用损耗采样机制的最佳采样比为1:1,在F1评分方面性能提高了1.1%。

5.3. Effect of Ordinal Loss
顺序损失的影响如表4所示。顺序损失在一定程度上提高了AP和AR。在权重最优的情况下,F1成绩提高了1.8%。

5.4 Comparison with Rule-Based Algorithm
我们比较了AssociationNet与传统基于规则的算法的性能,如表5所示。值得注意的是,虽然使用传统的基于规则的算法来生成关联标签来监督AssociationNet的训练,但AssociationNet的性能明显优于基于规则的替代方法。这说明了基于学习的算法在处理中固有的鲁棒性
