
论文笔记,原创内容;未经许可,请勿转载
说明
近期接触异类传感器信息融合领域,这里将之前论文进行提炼和总结,主要是对以下两篇论文的方法进行讲解。
由于本人最近接触这个领域,所述内容可能比较基础,请见谅。
主要讲述文献:
- Li Y, Zhao H, Hu Z, et al. IVFuseNet: Fusion of infrared and visible light images for depth prediction[J]. Information Fusion, 2020, 58: 1-12.
- Nobis F, Geisslinger M, Weber M, et al. A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection[C]//2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF). IEEE, 2019: 1-7.
红外与可见光进行融合:IVFuseNet
红外与可见光信息的互补性
红外与可见光信息存在**“互补性”**,具体体现为
-
可见光图像特点
- 大多数研究工作基于可见光进行识别和分类,相关方法比较成熟
- 光照情况好的情况下,可见光对物体的轮廓,纹理信息的提取更好
-
红外图像特点
- 红外图像不受亮度变化影响
- 红外图像具有高穿透力
- 红外检测距离远高于可见光的检测距离
- 红外图像缺乏纹理信息,对比度较低

IVFuseNet
Li Y(华东理工大学-赵海涛课题组)提出了一种基于CNN的融合架构,称为IVFuseNet(下图),能自适应融合红外和可见光图像的互补信息,进行深度预测,它由共同特征融合子网络、全特征融合子网络和高分辨率重建子网络3个子网络组成。

- 共同特征融合子网络:
- 部分耦合滤波器 : 为了保持显著特征,我们在共特征融合子网络中提出部分耦合滤波器,在自适应加权融合前进一步增强特征。耦合滤波器有助于发现更有鉴别性的特征,这些特征很容易被彼此忽略。
- 全特征融合子网络
- 自适应加权融合策略: 首先,我们考虑了红外图像和可见光图像在不同场景下对深度预测的贡献不同。提出了自适应加权融合策略,其中系数矩阵表示两种图像的不同贡献。
- 高分辨率重建子网络:
- 残差密集卷积 RDC : 此外,融合特征的分辨率在卷积过程中降低,小于ground truth深度图像的分辨率。在深度预测之前,我们需要恢复融合特征的分辨率。受[28,29]的启发,**残差密集卷积(residual dense convolution, RDC)**在高分辨率重建中具有良好的性能。因此在高分辨率重建子网络中,我们在高分辨率重建子网络中采用RDC,也可以增强融合的特征。
共同特征融合子网络
网络结构

- 双流程结构
- AlexNet为每个流程的基础:对于每个流,我们使用AlexNet[33]作为基础,因为AlexNet的参数数量相对较小。共特征融合子网络的具体内容如表1所示。此外,我们还可以选择其他网络作为基准,如VggNet[34]。该子网以256×512分辨率的红外图像及其对应的可见光图像作为子网的输入。
- 部分耦合过滤器:与传统的双流CNN不同,我们在每个卷积层中设计部分耦合滤波器来学习红外和可见光图像之间的可转移特征。耦合比率如表2所示
- 反向传播BP:独立特征需要迭代修正一次,共享特征需要修正两次
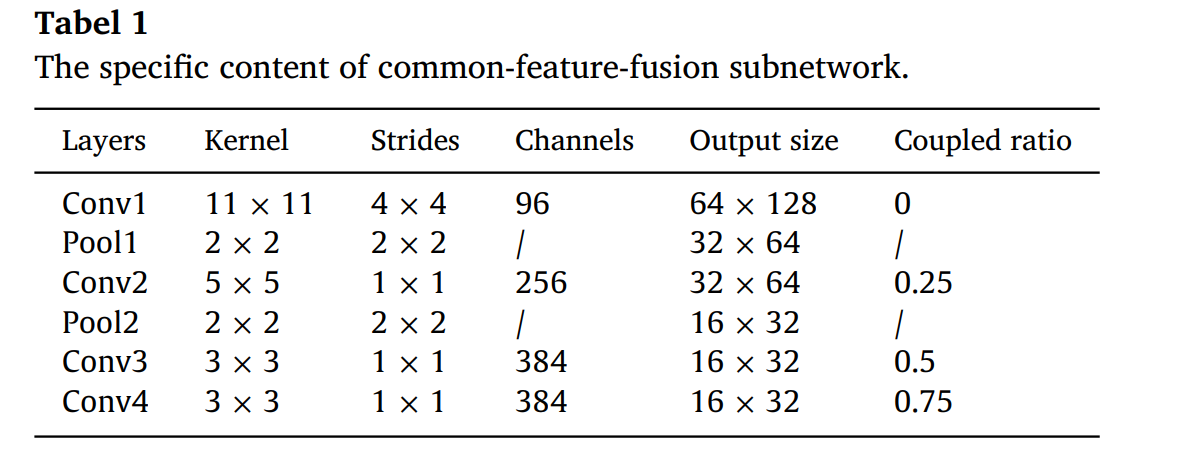
共同特征提取

耦合比设置
- 定义:R(耦合比) = k(耦合过滤器) / n (所有过滤器)
- 耦合比应该随着网络深度的增加而增加
- 设定为0, 0.25, 0.5, 0.75
- 解释:
- 浅层卷积层:提取图像的纹理和细节特征,红外与可见光中有很大的不同。
- 深层卷积层:提取图像的结构和形状特征,红外与可见光有很大的相同。
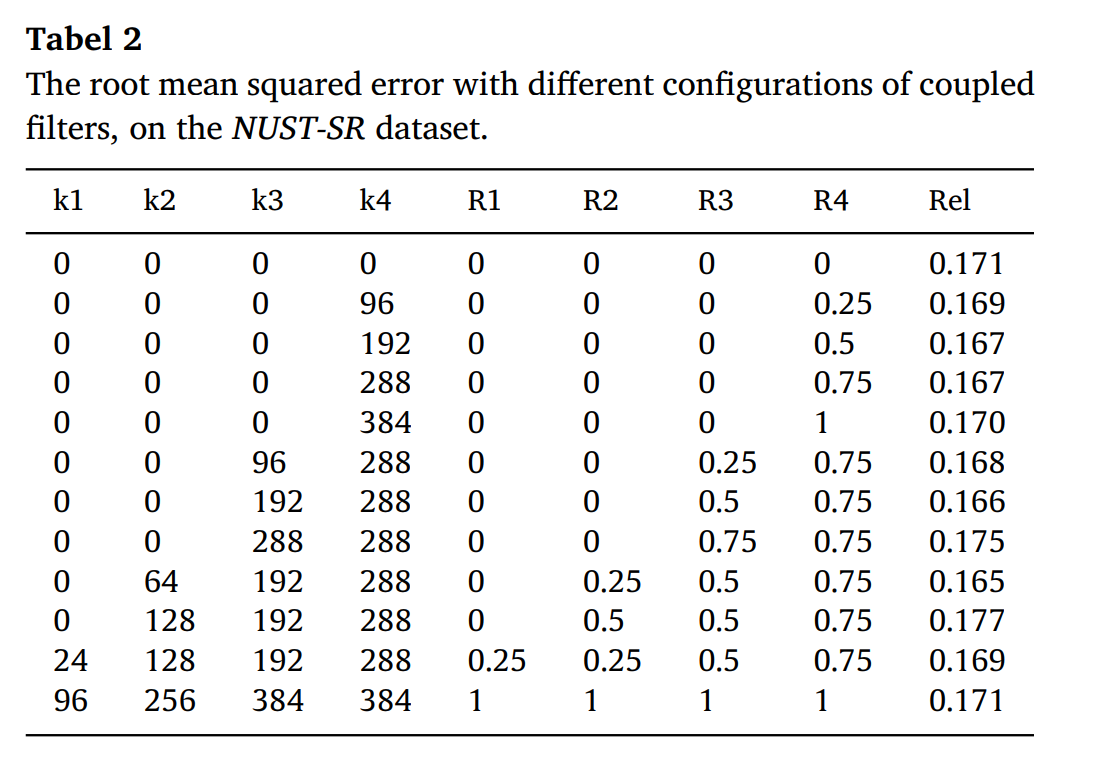
全特征融合子网络
融合步骤
设f_ir∈b×w×h×c和f_vi∈b×w×h×c是从共同特征融合子网络提取的特征
- 首先:我们将fir和fvi在第三个维度上进行拼接,这相当于融合f_fusion∈b×w×h×2c的红外图像和可见光图像的特征。
- 第二:将融合特征与核k∈2c×c×1×1进行卷积,其中2c为输入通道数,c为输出通道数,核大小为1×1。受[43]的启发,由于融合特征f_fusion同时考虑了红外和可见光图像的特征,因此该卷积运算的输出与这两种特征都有关。因此,这个程序学习了两种特征之间的相关性。在得到f_ir或f_vi的相同维数的初始系数矩阵M后,我们计算它们的点积,表示它们对不同场景深度预测的不同贡献。
- 第三,我们设计了一个sigmoid层,将M中的每个元素转换成0到1之间的概率形式。经过这三个步骤,最终得到系数矩阵G。其过程如下:

在不同的条件下,系数矩阵是不同的.例如,G_ir可能在暗光情况下比G_vi大而,G_vi可能在白天下比G_ir大.G_ir和G_vi分别表示红外图像和可见光图像特征的贡献,具体如下:

其中’圈点’代表点积.全融合特征可以这样得到:
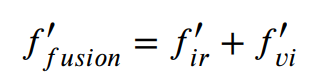
全特征融合子网络决定了红外特征和可见光特征对深度预测的依赖程度。
高分辨率重建子网络
网络结构
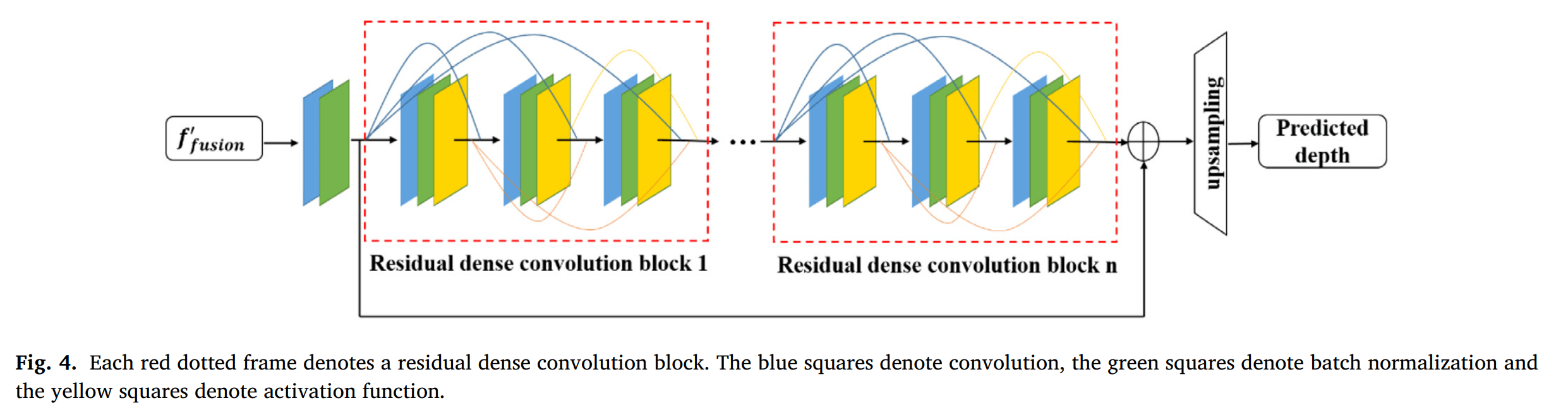
蓝色:卷积层;绿色:BN层;黄色:激活函数
残差密集卷积网络(Residual Dense Network,RDN)

大多数基于CNN的深度神经网络模型并没有充分利用原始低分辨率(LR)图像的分层特征,因此性能相对较低。
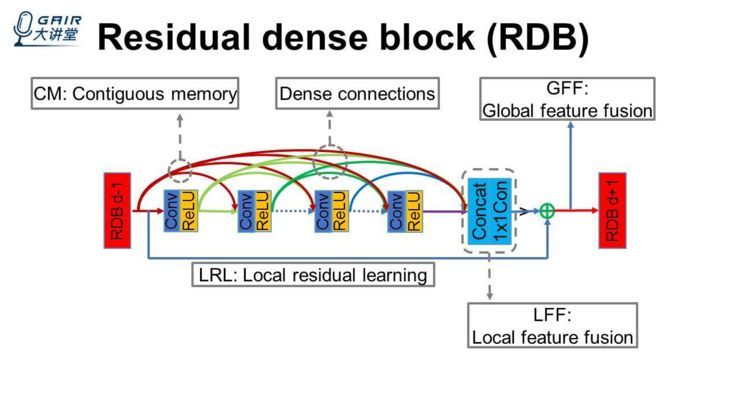

残差密集网络优点:
(1)充分的利用了所有卷积层的层次信息,通过密集连接卷积层提取丰富的卷积特征。
(2)允许从前一个RDB的状态直接连接到当前RDB的所有层,从而形成连续的内存(CM)机制。
(3)可以更有效地从先前和当前局部特征中学习更有效的特征,并稳定更广泛的网络的训练
将浅层特征和深层特征结合在一起,从原始 LR 图像中得到全局密集特征。
网络效果评价
评价标准
在NUST-SR数据集的测试图像上,我们使用四个指标对提出的IVFuseNet进行评估:
- 方均根误差(RMSE)
- 平均相对误差(Rel)
- 平均对数误差
- 识别准确率
红外与可见光融合的结果
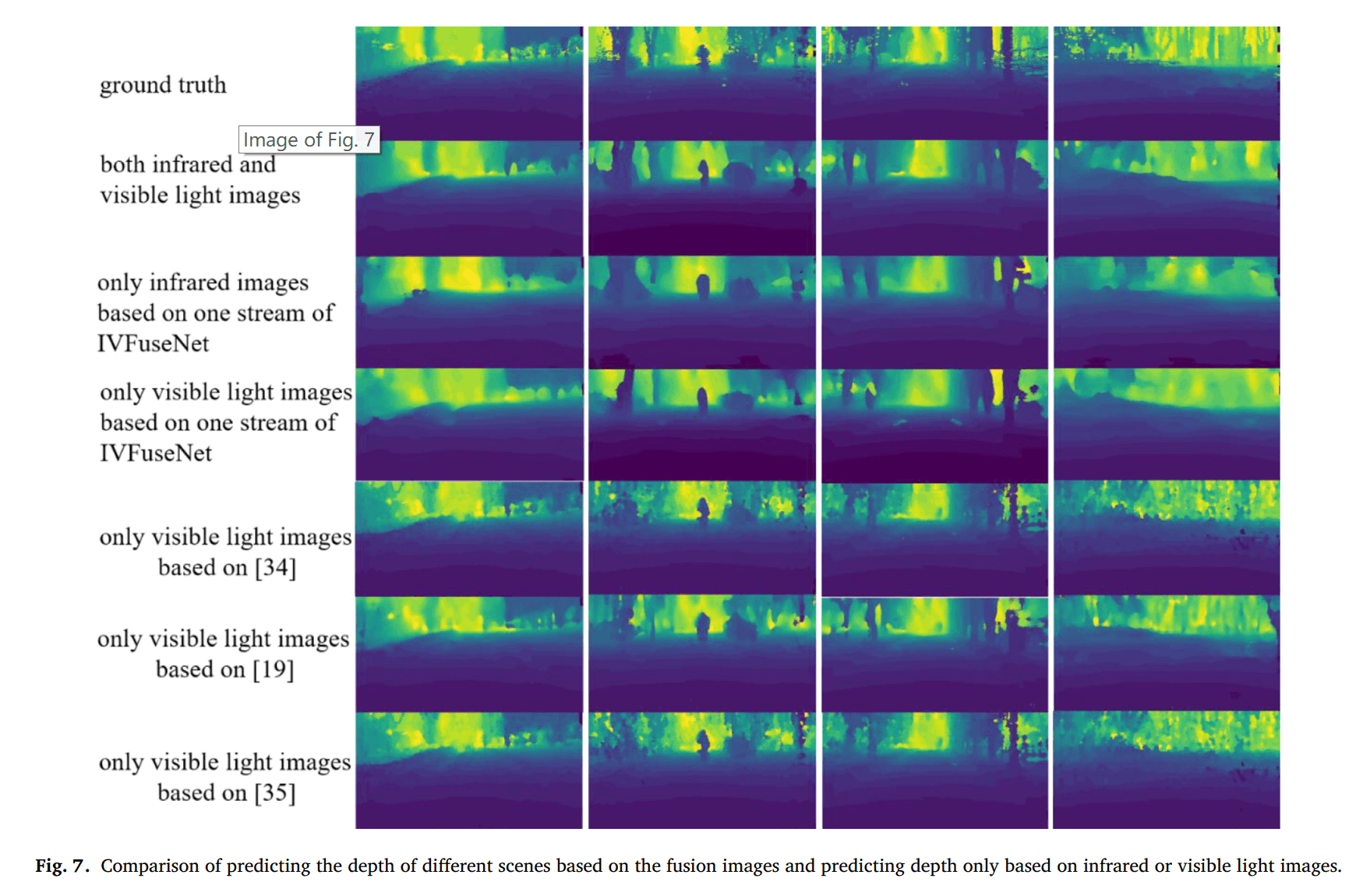
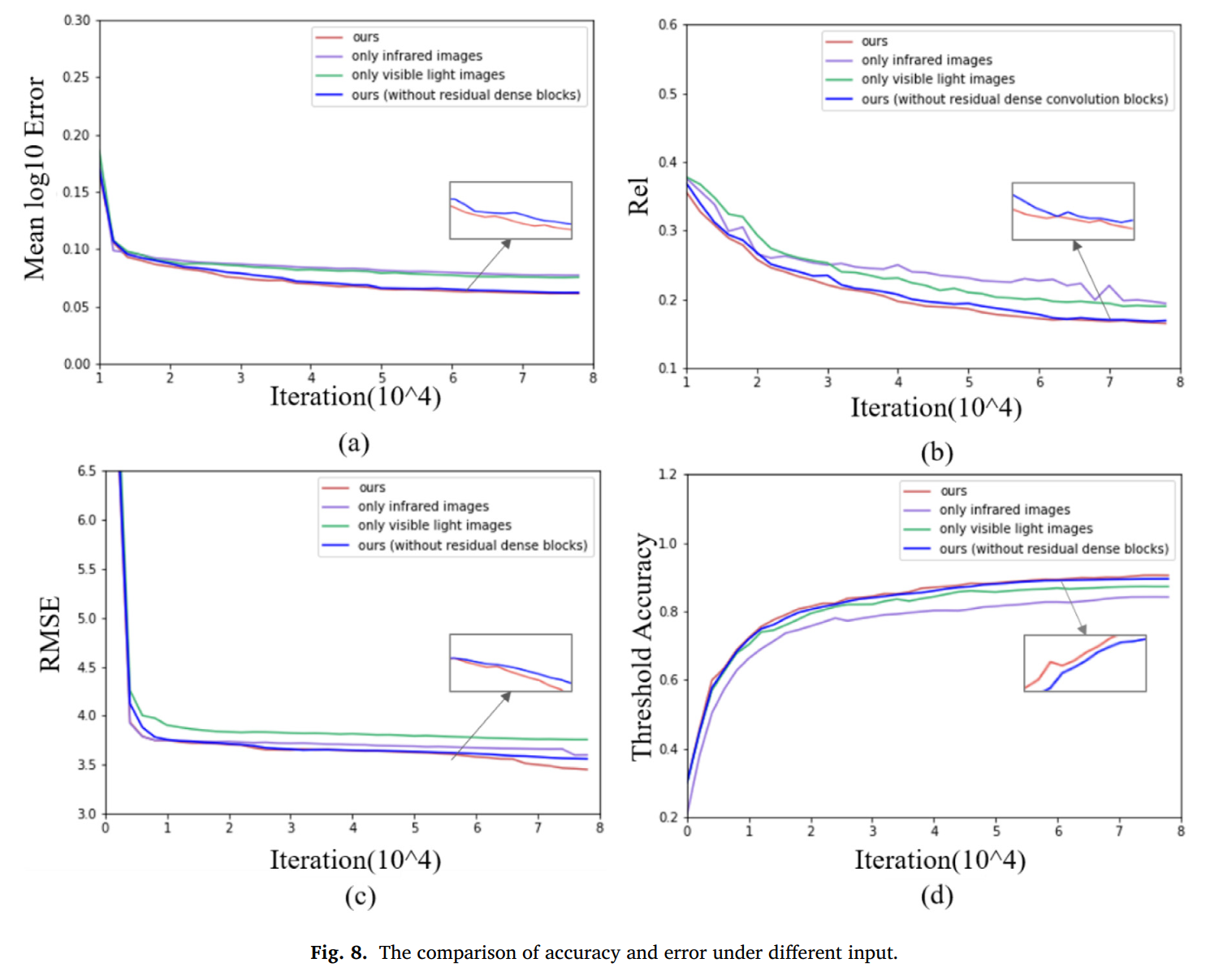

密集卷积块的结果


和相关方法的对比


主要贡献
- 我们提出了一种基于CNN的结构,称为IVFuseNet,它可以自适应融合红外和可见光图像的互补性,以解决不同光照条件下的深度预测问题。我们提出的融合方法主要包括两个方面。
- 首先,我们在共特征融合子网络中设计部分耦合过滤器,利用“辅助变量”增强红外和可见光图像的特征。
- 其次,为了考虑不同光照条件下红外和可见光图像的不同贡献,设计了自适应加权融合方法。
- 此外,我们引入3个残差密集卷积块,进一步恢复细节,提高深度预测的准确性.
- IVFuseNet的有效性已经在我们的NUST-SR数据集上得到了验证。与其他方法相比,我们在该数据集上取得了最好的性能。
雷达与可见光融合:CRF-Net
雷达与可见光数据的特点
雷达:直接获取目标的距离和径向速度信息。它能够在与地面平行的二维平面上定位物体。与相机相比,雷达传感器无法获得高度信息。
相机数据特点:在视觉平面中获得二维的密集的纹理,色彩,轮廓信息图。
雷达数据处理
雷达数据的处理主要有四点问题:
- 雷达和相机数据的空间校准
- 如何应对雷达回波丢失的高度信息
- 如何应对雷达数据的稀疏性
- 用真实标注信息滤波(ground-truth filtering, GF)方法来消除雷达数据的噪声和杂波
雷达和相机数据空间校准
雷达输出的是具有雷达性质的2D-稀疏-点云信息,本工作中应用的雷达信息主要有方位角,距离,雷达散射截面(radar cross section, RCS)。我们将雷达信息从2D地面平面转换到了图像面的垂直面上。雷达回波信息被在扩维图像(augmented image)上面被保存为像素。无雷达回波的位置上,投影的雷达通道值的像素被标记为0。输入的相机图片信息包含三通道(红,绿,蓝);我们将先前提到的雷达通道作为神经网络的输入。在我们的数据集中,三个雷达的the field of view(FOV)和前视鱼眼相机的FOV重合。我们将三个雷达点云信息合并到一个中去,然后利用这个作为投影雷达输入信息源。投影的算法不尽相同,例如nuScenes利用70°FOV相机,但是TUM利用180°FOV鱼眼相机。在nuScenes中,提供了摄像机内外映射矩阵,用于将点从世界坐标转换为图像坐标。而鱼眼透镜的非线性不能用线性矩阵运算来映射。我们使用[28]提供的校准方法将世界坐标映射到我们自己的图像坐标。
总结重点:
- 三个雷达点云信息合并为一个,作为雷达信息源
- 雷达信息源投影到图像平面上
- 鱼眼相机的世界坐标投影到图像坐标上
- 投影雷达数据作为图像信息的扩维,无回波的地方像素就为0
应对雷达高度信息缺失
-
首先考虑到我们检测的目标主要是车,卡车,摩托车,自行车和行人
-
我们假设了雷达得到的回波点的高度都是3m,以覆盖这些目标的高度
-
然后这个高度线也作为像素投影到了图像平面
应对雷达信息的稀疏性
- nuScene中激光雷达一次返回约14000点(相同水平张角下)[29], 这大概等同于雷达每周期探测57次的信息量.
- 为了解决稀疏性问题,[25]利用了概率网格图(probabilistic grid maps)来获得雷达的连续性信息.
- 我们通过融合最后13次雷达周期(约1s)的图像来提高雷达数据的密度.
- 在这个方法中,我们补偿了自身运动(Ego-motion),但是目标车辆的运动无法补偿
- 这种方法也增加了噪声,因为前一时刻对移动目标的检测与当前目标物体的位置不一致.但是为了增加额外信息,这个缺点是可以忍受的.
- 下图展示了神经网络的输入数据的形式,雷达数据(距离和RCS)被标记在相同位置所以这里有均匀的颜色

雷达数据的滤波
雷达回波会返回需要与目标无关的检测信息,例如幽灵目标,无关目标和地面检测. 这些检测信息就是所说的噪声或杂波。在评价中,我们比较了融合原始雷达数据和利用两种额外滤波方法的雷达数据融合的效果。首先在nuScene中,只有一些标记目标被雷达检测到。在训练和估计中,我们因此实施了一种注解标注滤波器(annotation filter,AF),这样经过滤波后的真实标注信息只包含至少同时被雷达点检测到的目标。这种方法对于可能被两种模式检测到的目标能发挥它的潜力。第二,我们采用了真实标注信息滤波器ground-truth filter来移除3D真实标注信息边界外的雷达探测点。当然,这个步骤如果实际场景是无法进行的。本文的目的是在输入信号杂波较少的情况下,证明融合概念的普遍可行性。经过雷达滤波后的图像在图像2b中被展示。注意,**GRF(ground-truth radar filter)**并没有输出完美的雷达数据,其中滤掉了部分数据的相关检测,原因有四:…(总结中有)

总结:
- 两种滤波器:
- AF:过滤没有同时被雷达数据检测到的目标
- GRF:过滤超出真实标注边界的目标
- 滤波无法输出完美雷达数据的四点原因:
- 没有对运动目标的补偿。雷达探测频率2Hz,探测周期中间的目标可能就消失了
- 雷达数据和相机数据具有轻微的空间错校准
- 雷达数据和相机数据不是刚好都是同一时间产生的
- 虽然雷达距离测量非常可靠,但其测量并不完美,轻微的误差就会导致探测落在真实标注边界之外。在图2b中可以看到对部分相关数据进行了无意的过滤
网络结构
- 为什么不能直接融合(在第一层就开始融合)?
雷达投影数据中的像素与图像数据中的像素意义是不同的,前者代表了目标的距离,对于驾驶任务更为相关。如果要直接融合这两种数据,我们需要假设他们是语义近似的;然而,由于上一点的原因,我们显然难以做出这种假设!
- 那如何融合?
在神经网络的更深层,输入数据被压缩为更密的形式,这种形式理想上包含所有相关的输入信息。即然我们无法确定两种传感器类型的信息的抽象层次,我们将网络设计为自主学习在哪种层次进行融合最有利于减少全局损失的形式。

- 网络介绍
- 相机和雷达数据在顶排被输送给该网络。
- 在左侧,原始雷达数据通过[^max-pooling]来改变尺寸以送进更深的网络层。
- 雷达数据被合并到前一级融合网络层的主要分支上
- 特征金字塔网络(Feature Pyramid Network, FPN)[33],其中雷达数据被分级融合进去,通过将雷达通道合并到额外的通道上去
- 最后FPN的输出通过回归和分类块进行处理[30]
- 网络优势
-
通过调节雷达特征在各个层的权值,优化器隐式地教会了该网络在何种深度将雷达数据进行融合具有最好的影响
-
类似的技术被[16]所采用
-
训练策略
- BlackIn :有意在部分训练中禁用了所有图像数据输入神经元,这个比例大概是0.2。这样做的目的是:图像数据的丢失能更加刺激该网络更依赖于雷达数据。‘教育’该网络稀疏的雷达数据是独立于密集的图像数据的。
- 用预先在图像上训练的权重开始训练,用于特征提取器。
效果评价
数据集

评价

一个例子
下图的对比能很好低表现CRF-Net的优势:

主要贡献
- 提出了CRF-Net结构来融合雷达和相机数据
- 本研究适应了激光雷达和相机数据处理的思路,为雷达数据融合研究开辟了新的方向。
- 对雷达数据处理的难点和解决方案进行了讨论
- 引入了BlackIn训练策略进行雷达和相机数据的融合。
- 证明了采用神经网络对雷达和摄像机数据进行融合,可以有效地提高目前最先进的目标检测网络的精度
- 由于对雷达与相机数据的神经网络融合的研究是最近才开始的,寻找优化的网络架构还需要进一步的探索。
基础知识
特征融合方式(concat 与 add)
concat层的作用就是将两个及以上的特征图按照在channel或num维度上进行拼接
concat : channel或者宽度增加,不是叠加
add:不改变维度,只是叠加
当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。
参考资料:https://blog.csdn.net/qq_32256033/article/details/89516738
https://www.zhihu.com/question/306213462/answer/562776112
反卷积(deconvolution)
反卷积(deconvolution):更好的说法是转置卷积,是一种上采样的方式,同样利用卷积使得图片的分辨率变大
4*4的输入矩阵可展开为16维向量x
2*2的输出矩阵可展开为4维向量y
卷积运算可表示为y = Cx,则反卷积运算可以表示为x = C‘y,将图片的维数放大
上采样(upsampling)
上采样:上采样是指将图像上采样到更高分辨率的任何技术。最简单的方法是使用重新采样和插值。即取原始图像输入,将其重新缩放到所需的大小,然后使用插值方法(如双线性插值)计算每个点处的像素值。
将图片的分辨率变大的操作,有关上采样的改进案例:https://distill.pub/2016/deconv-checkerboard/
批归一化(batch normalization,BN)
批归一化(batch normalization,BN):一般在激活层之前,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。参考:
- https://www.cnblogs.com/mfryf/p/11381361.html#ct2
- https://blog.csdn.net/qq_42219077/article/details/88379566
池化(pooling)
池化的原理或者是过程:pooling是在不同的通道上分开执行的(就是池化操作不改变通道数),且不需要参数控制。然后根据窗口大小进行相应的操作。一般有max pooling、average pooling等。
- 池化层主要的作用
- 首要作用,下采样(downsamping)
- 降维、去除冗余信息、对特征进行压缩、简化网络复杂度、减少计算量、减少内存消耗等等。各种说辞吧,总的理解就是减少数量。
- 实现非线性(这个可以想一下,relu函数,是不是有点类似的感觉?)。
- 可以扩大感知野
- 可以实现不变性,其中不变性包括,平移不变性、旋转不变性和尺度不变性。
参考连接:
- https://zhuanlan.zhihu.com/p/27642620
- https://www.zhihu.com/question/36686900
- https://blog.csdn.net/LIYUAN123ZHOUHUI/article/details/61920796
VGG
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。下图是一个用3层3x3代替5x5的例子
RetinaNet(Focal Loss):
RetinaNet由以下处理步骤组成提取、特征金字塔网络(FPN)和用于分类和回归的检测头。
- Focal loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
目标识别有两大经典结构:
-
第一类是以Faster RCNN为代表的两级识别方法,这种结构的第一级专注于proposal的提取,第二级则对提取出的proposal进行分类和精确坐标回归。两级结构准确度较高,但因为第二级需要单独对每个proposal进行分类/回归,速度就打了折扣;
-
第二类结构是以YOLO和SSD为代表的单级结构,它们摒弃了提取proposal的过程,只用一级就完成了识别/回归,虽然速度较快但准确率远远比不上两级结构。
那有没有办法在单级结构中也能实现较高的准确度呢?Focal Loss就是要解决这个问题。
- 检测框架
RetinaNet本质上是 Resnet + FPN + 两个FCN子网络。
以下为RetinaNet目标框架框架图。有了之前blog里面提到的FPN与FCN的知识后,我们很容易理解此框架的设计含义。

参考内容: