
论文笔记,原创内容;未经许可,请勿转载
Abstract
目前有许多文献提出了利用各种不同传感器和融合方法的融合框架。目前,提升精度表现吸引了更多的注意;然而,在实际车辆上的实施的可行性很少受到关注。一些融合框架在实验室里用高性能平台可以得到很好的结果;但是在实际应用中,由于他们昂贵的加个和大量的计算需求,不能被应用在嵌入式计算机上。我们提出了一种新型的混合多传感器融合通道配置,为自动驾驶车辆执行环境感知,如道路分割、障碍检测和跟踪。这种融合框架使用所提出的**基于编码-解码的全卷积神经网络(encoder-decoder based Fully Convolutional Neural Network, FCNx)和传统的扩展卡尔曼滤波器(Extended Kalman Filter, EKF)**非线性状态估计方法。该混合框架的目标是提供一个成本效益高、轻量级、模块化和强鲁棒性(在传感器故障情况下)的融合系统解决方案。它使用了FCNx算法,相比于基准模型提高了道路检测的准确性,同时保持了实时效率,可用于自主车辆嵌入式计算机。在超过3000个道路场景上的测试表明,我们的融合算法相比于基本网络算法显示出了更好的性能表现。除此之外,该算法被部署到了实际车辆上并且利用车辆收集到的数据进行测试,进行了实时的环境感知。
why?:现有算法只关注了精度提升,没有关注可实施性
how?:FCNx + EKF
result?:1.比现有算法的更好性能表现 2.被部署到了实际车辆上进行了实时感知
Introduction
P1:自动驾驶车辆的工作流程
自动驾驶车辆(autonomous vehicles, AV)需要解决的两个主要问题:
- 自我定位——我自己在哪?:GNSS,IMU,vehicle odometry(里程记)
- 环境感知——我旁边有些什么?:LiDAR, camera,radar
定位和感知的结果被送到AV的路径规划算法中来决定下一步的动作。这些动作进一步送到电机控制器上来控制车辆运动。图1显示了这个工作流程:

P2:问题引入
当前环境感知的研究主要包括传感器信号处理和各种融合算法
- 传感器类别:相机,激光雷达,雷达
- 融合算法类别:
- 状态估计融合算法(i.e. KF)
- 基于机器学习的算法(i.e. deep neural network, DNN)
当前的研究还是侧重于精度的提升而没有考虑部署的可能性,所以需要一种高效,轻量,模块化和鲁棒的流程。因此我们需要能一种平衡融合融合模型的复杂度和真实世界实时应用性,且同时能提升环境感知精度的算法。
P3:本文结构
- 第二节:回顾传感器融合文献
- 第三节:回顾和我们用的传感器相关的感知技术
- 第四节:展示我们所利用的传感器融合流程概览,并且展示如何处理传感器数据和实施融合方法(即我们的FCNx的细节和传统EKF的回顾)
- 第五节:实验流程,工具和数据集
- 第六节:实验结果和评估
- 第七节:结论
Fusion Systems Literature Review
融合系统文献回顾
-
[1-5]:关注于相机和激光雷达的融合,利用深度学习方法来进行各种计算机视觉的任务
-
[6]:关注于单传感器(相机或激光雷达)和单一方法(深度学习或者传统计算机视觉)的技术
-
[1,2,7]:关注于激光雷达+相机和一种融合方法
-
[8-10]:关注于激光雷达+雷达+相机和状态估计方法(卡尔曼滤波或例子滤波)
-
[11]:不考虑实际世界部署或者传感器的特殊情况的融合方法,回顾了自动驾驶车辆系统的技术
-
[12]:回顾了环境感知算法和介绍了智能车辆,包括车道和道路检测、交通标志识别、车辆跟踪、行为分析和场景理解的建模方法。
-
[13]:回顾了传感器和传感器融合方法
-
[6]:使用两种分离的CNN网络提出了一个RGBD目标检测架构
-
[1,2]:利用快速决策树分类器(boosted decision tree
classifier)融合激光雷达和相机数据,进行道路检测 -
[3]:利用几何变换,提出了一种基于视觉的道路检测方法
-
[4]:提出了一种统一的方法来进行联合分类、检测和语义分割,重点关注效率。
-
[14]:仅仅利用激光雷达,利用FCN来进行基于深度学习的路面检测
-
[15]:提出了一种高维传感器融合架构并且在ADAS系统上进行了测试,例如紧急刹车辅助。
-
[16]:融合相机和激光雷达点云数据,利用几种FCNs和不同的融合策略:早期、中期和后期融合来进行路面检测
-
[17]:利用毫米波雷达和单色相机(mono camera)融合来进行车辆检测和跟踪
-
[18]:展示了一种叫做"SegNet"的解码-编码FCN进行道路和室内图像的像素语义分割
-
[7]:提出了一种用于传感器融合的深度学习框架ChiNet,该框架利用立体摄像机在不同的分支上融合深度和外观特征。ChiNet有两个输入分支用于深度和外观,两个输出分支用于道路和对象的分割
-
[8]:提出了一种基于二维激光扫描仪和摄像机传感器的融合系统,结合**无迹卡尔曼滤波(UKF)**和联合概率数据关联来检测车辆
-
[9]:利用UKF来融合传感器数据来研究室内的轮椅位置估计问题
-
[5]:提出了一种基于深度学习的基于激光雷达和摄像机的端到端城市驾驶融合框架
-
[19]:采用两阶段融合的方式,利用立体相机和激光雷达提升车辆检测的性能
-
[20]:争对复杂城市场景,利用CNN和KF,融合相机,2d激光雷达和先验地理道路地图,提出了一种车辆检测和跟踪系统
-
[21]:提出了一个用于行人、自行车和车辆检测的摄像头系统,然后使用雷达和激光雷达改进跟踪和运动分类。
-
[22]:提出了一种基于热敏摄像机和RGB摄像机深度学习的多光谱行人检测系统
-
[23]:提出了一种卷积神经网络进行语义分割——全卷积神经网络(fully convolutional network, FCN)
-
[24]:改进了[23]的结构,提出了反卷积网络(DeconvNet),使用带有反卷积滤波器的解码层对下采样的特征图进行上采样。
-
[25]:利用编码器层和解码器层之间的连接改进了DeconvNet。在U-Net中,另一种基于编码器-解码器的结构用于语义分割,所有的特征映射都通过剩余连接从编码层转移到解码层。
-
[26]:Mask-RCNN
-
[27]:Fast - RCNN
我们的目标:提供一种低成本,轻量化的融合系统,它可以被部署到相对便宜和高效的嵌入式边缘计算电脑上
Autonomous Vehicle Perception Sensors
本文使用的传感器
本文使用三种传感器,他们的位置分布如下
相机:受到环境变化例如:遮挡、光照和天气变化
LiDRA:受到雨、雪恶劣天气影响
雷达:低探测率和低分辨率
使用三种传感器并采用合适的传感器融合算法有助于确定各种传感器的失效情况。同时提高了整体的误差容限和精度。

相机
P1:相机的工作原理
-
相机是进行高分辨率的任务:类似目标分类、语义分割、场景感知和需要色彩感知的任务类似交通灯或信号确认的重要传感器。
-
镜头接受光→感光元件(CCD or CMOS)→ADC(AD转换器)→ISP(image signal processor)→RGB pattern
-
物体位置[x,y,z] → (透镜)→ 像平面[x’, y’]
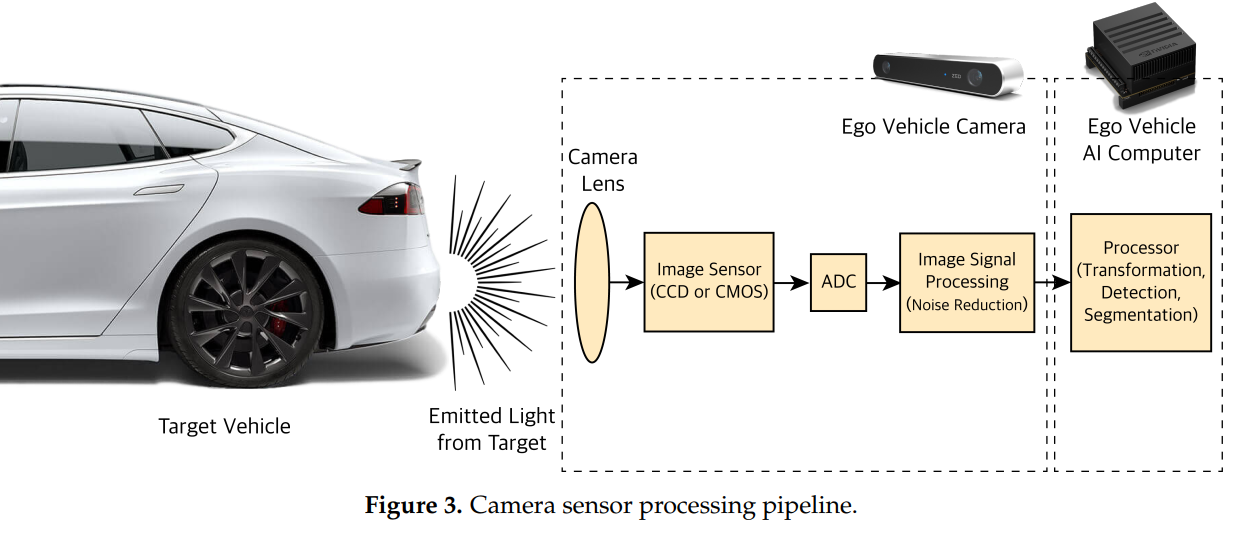
P2:相机的校准,两种感光元件
-
校准相机:由于镜头扭曲了生成的图像,需要先对每个相机进行校准。
-
校准方法:我们通过使用已知物体的图片(如棋盘)来矫正这些失真。棋盘的尺寸和几何形状是已知的;因此,对于那些扭曲,我们就可以计算通过相机输出图像与原始图像的比较来标定参数。
-
两种感光元件
CCD(Charge-Coupled Device) : 高光敏感度,更好的成像质量,耗电更好,发热大,价格贵
CMOS(Complementary Metal Oxide Semiconductor):低成本,低耗电量,数据处理更快——我们采用
雷达
P1:雷达的工作原理
-
测量原理:雷达可以测量障碍物的相对位置信息(基于电磁波的传播时间)和相对速度(基于Doppler效应)
-
环境天气影响:电磁波不会受到不同光线和天气条件的影响
-
安装位置:汽车雷达通常安装在保险杠后或在车辆格栅;车辆的设计是为了确保雷达性能(雷达天线聚焦电磁能量的能力)不受影响,无论它们安装在哪里。
-
FMCW:对于自动驾驶车辆,通常使用调频连续波雷达(Frequency-Modulated
Continuous Wave,FMCW)[29]。FMCW雷达发射连续波或线性调频信号,其中频率随时间增加(或减少),通常呈锯齿形 -
MMW: 这些雷达通常工作在24,77,79GHz频段,对应于毫米级波长,所以也称之为毫米波雷达(millimeter wave) radar。根据应用可以分为三种
- SRR(Short-Range Radar):辅助泊车,碰撞警告
- MMR(Medium-Range Radar):盲点检测,侧/后方防撞
- LRR(Long-Range Radar):自适应巡航,前方早期碰撞检测

P2:FMCW雷达工作流程
有关雷达工作的主要流程,主要理解下列元件的作用即可,这部分略
- Frequency Synthesizer
- power amplifier
- transmit (TX) antenna
- receive (RX) antenna
- LNA(Low Noise Amplifier)
- Mixer
- ADC(analog digital converter )
激光雷达
P1:激光雷达的工作原理
-
工作原理:发射激光或红外(IR)光束,接收光束的反射来测量周围环境。用于自动驾驶汽车的激光雷达大多波长在900纳米(nm),但有些波长更长,在雾或雨中工作得更好。
-
输出:激光雷达输出点云数据(point cloud data, PCD), 其包含物体位置(x,y,z)和强度信息。强度值表示物体的反射率(物体反射的光量)。利用光速和飞行时间(time of flight, ToF)来检测物体的位置。
-
两种类型
- 机械/转子激光雷达:使用电机旋转来发射和接受激光/红外线
- 固体态激光雷达(Solid State LiDAR, SSL):没有任何旋转镜头来引导激光;相反,他们用电子方式控制激光。这些激光雷达比机械激光雷达更坚固、可靠、更便宜,但其缺点是与机械激光雷达相比,它们的体积更小,FoV更有限。
-
人体危害:LiDAR输出的是最弱的1类激光,对人体无害

P2:激光雷达的工作流程
- 激光由二极管产生
- 通过旋转镜头将能量聚焦到各个角度上
- 光被反射后背另外一套旋转镜头接受
- 计时器计算ToF来确定目标位置信息
- 产生的点云信息传递给其他设备
P3:激光雷达的特点
-
和相机相比:
- 相同点,LiDAR产生2D空间信息
- 不同点:不同的是,它通过获得距离来创建3D空间环境信息。通过测量距离,LiDAR提升了角分辨率(水平和垂直方向)相比于相机获得了更好的量测精度。
-
和雷达相比:
- 激光雷达具有更高频率和更短的波长,更精确
-
典型的激光雷达精度:
-
测量距离:40-100m
-
分辨率精度1.5-10cm
-
垂直角分辨率:0.35-2度
-
水平角分辨率:0.2度
-
采样频率:10-20Hz
-
Hybrid Sensor Fusion Algorithm Overview
混合传感器融合算法概述
算法分为两个部分,他们彼此并行,如图6。在每个子部分中,选用了最适合当前任务的一系列传感器参数和融合方法。
算法第一部分:LiDAR + camera
-
处理高分辨率任务:如目标分类,定位和道路语义分割
-
使用LiDAR + camera
-
卷积神经网络CNN和全卷积网络FCN相比于传统方法,即特征提取器(SIFT, HOG)具有更好的性能表现
-
FCN结构的融合是最好的
-
我们优先考虑实时性能和精度,所以我们没有像[32]中那样将道路场景分割为多个场景进行分割,我们只分割了两类:可驾驶区域和不可驾驶区域
-
我们还利用了高效和快速的网络例如YOLO V3[33]来探测分割后路面的障碍物。
算法第二部分:LiDAR + radar
- 处理目标检测和状态跟踪任务
- 使用LiDAR + radar
- 两种传感器的数据在目标层(object level)进行融合
- 激光雷达和雷达数据处理会在感兴趣区域(ROI)内产生障碍物簇及其状态。处理后的传感器数据在目标层上的融合称为后期融合。结果融合后的激光雷达和雷达数据被发送到一种状态估计方法,以最佳组合每个传感器的噪声测量状态。
- 状态估计方法采用KF,但是是争对线性模型的
- 因为像汽车这样的障碍物的运动是非线性的;我们使用改进版的KF,即扩展卡尔曼滤波器(EKF)。了解和跟踪道路上障碍物的状态有助于预测和解释它们在AV路径规划和决策堆栈中的行为。最后,我们覆盖每个融合输出并在汽车监视器上显示它们
利用深度学习进行目标分类和道路分割
-
raw data combine
-
RGBD图像,其中D为深度通道
-
将这些数据传输给我们提出的全卷积层神经网络FCNx
-
**FCNx is an encoder-decoder-based network with modified filter numbers and sizes in the downsampling and upsampling portions and improved skip connections to the decoder section. **
-
FCNx是一种基于编码-解码的网络,它拥有一些在下采样和上采样过程中,数量和大小参数都修正过的滤波器;还在解码环节拥有改进跳跃连接。
相机-激光雷达Raw Data融合
- 数据准备:
- 相机:2D图像,RGB
- 激光雷达:除了点云图像,还有高分辨率深度图
- 早期融合:
- 我们将raw data结合在了一起
- 得到RGBD图像
- 融合过程:
- to FCN:进行道路语义分割
- to CNN:目标检测和定位

全卷积神经网络结构FCNx
结构包括两个主要部分:编码器和解码器
- 编码器:
- 基于VGG16[34]
- VGG16的全连接层替换为卷积层
- 编码器的目的是从RGBD图像提取特征和空间信息
- 它使用一系列的卷积层来提取特征,池化层来减小特征图的尺寸
- 解码器:
- 基于FCN8[23]
- 其目的是在保持低、高层信息完整性的前提下,将像素类的预测重新恢复到原始图像大小。
- 它采用转置的卷积层来对编码器的最后一个卷积层的输出进行采样
- 它还采用跳跃卷积层来结合来自编码器的精细的低等级特征(finer low-level features)和转置(上采样)卷积层的粗糙的高等级特征(coarser high-level features)。

网络结构介绍:
-
将第四层的编码层的输出和第七层上采样层结合。这个结合是元素意义上的合并。这个结合后的特征图被添加到第三层的跳跃连接上。
-
…
原文直接抛出来把,这里太乱了…给我看晕了都
In our proposed network, which builds on the above shown in Figure 8, we combine the encoder output from layer four with the upsampled layer seven. This combination is an element-wise addition. This combined feature map is then added to the output of the third layer skip connection. In the skip connection of the layer three output, we use a second convolutional layer to further extract features from layer three output. The addition of this convolutional layer adds some features that would be extracted in layer four. Including some basic layer four level feature maps will help the layer three skip connection to represent a combined feature map of layer three and layer four. This combined feature map is then added to the upsampled layer nine, which itself represents a combined feature map of layer seven and layer four. This addition is shown to give a better accuracy and lower Cross-Entropy loss compared to the base VGG16-FCN8 architecture. The better performance can be explained by the fact that having some similar layer four feature maps can help better align the extracted features when performing the last addition. We will refer to our proposed architecture as FCNx
-
优点:相比于基础的VGG16-FCN8网络,拥有更高的精度和更低的交叉熵损失(lower Cross-Entropy loss)
-
原因:当进行最后的添加操作时,拥有比较相似的四个特征图可以帮助更好地对齐提取的特征。
利用kalman滤波进行障碍物检测和跟踪实验
在本节中,我们利用雷达和激光雷达数据来检测障碍物和测量他们的状态。我们进行了后数据融合或者说是目标级的融合。然后,利用非线性卡尔曼滤波方法,利用这些噪声传感器来估计和跟踪障碍物状态,其精度比单个传感器都要高。
雷达拍频信号(beat signal)处理
雷达传感器可以探测到障碍物和他们的状态,通过图9的过程:

-
第一步:带噪声信号 → (雷达内部ADC) → 数字信号
- 处理从雷达接收到的有噪声的数字化混合信号或拍频信号。拍频信号通过雷达内部的ADC发送,并转换为数字信号。数字信号在时域内,由多频分量组成。
-
第二步:时域信号 → (1D-FFT) → 频域信号
-
1D - FFT也被称为1st stage or Range FFT。分离它的全部频率分量。FFT的结果是被单位为dBm代表的信号强度或者分值,横坐标是拍频的频率MHz。每个频率峰代表一个检测到的目标。
-
x轴可以从目标的拍频的频率转换为目标的距离,通过公式:
-
$$
R=\frac{c \cdot T_{\text {sweep}} \cdot f_{b}}{2 \cdot B_{\text {sweep}}}
$$
-
其中R:目标距离;c:光速;T_sweep & B_sweep:啁啾/扫描时间和带宽
-
T_sweep & B_sweep的计算公式:
$$
T_{\text {sweep}}=5.5 \cdot \frac{2 \cdot R_{\max }}{c}
$$
$$
B_{\text {swee } p}=\frac{c}{2 \cdot d_{\text {res}}}
$$
- R_max是最大距离,d_res是雷达距离分辨率。常数5.5来自假设:对应于最大雷达扫描距离,扫描时间通常是延迟的5-6倍
如上所讨论的,range FFT可以告诉我们拍频,峰值,相位和距离。为了测量目标的速度(Doppler velocity),我们需要找到多普勒频移,即雷达chirps的相位变化率。目标从一个chirps变化到另外一个。因此,在得到range FFT后,进行第三步。
-
第三步:Doppler FFT 测量相位的变化率——多普勒频移
-
输出结果是一个3D图,分别由信号强度,距离和多普勒速度代表
-
这个3D图也叫做**(Range Doppler Map, RDM)**。RDM给出了我们目标的距离和速度的概览

-
第四步:过滤RDM的噪声和杂波
-
最常用方法:Cell Averaging CFAR (CA-CFAR) [38]
CFAR : 它会根据信号局部噪声的大小动态调整阈值,如图10,CA-CFAR在我们生成的2D FFT图像上生成一个滑动窗口。窗口包括:
- Cell Under Test (CUT):正在被测试目标是否出现的格子
- guard cells (GC):CUT附近的格子,防止目标信号泄漏到周围的单元,从而对噪声估计产生负面影响
- reference or training cells (RC) :包住CUT周围环境的格子
噪声的等级是根据RC的平均值来估计的,如果CUT中的信号比该阈值低,则它被去除;如果比阈值高,那么就认为检测到了目标。
-
最后,我们实现了具有距离和多普勒速度信息的雷达CFAR检测,但目标的实时检测和跟踪是一个计算量大的过程。因此,我们将属于同一障碍物的雷达检测聚类在一起,以提升该流程的性能。我们使用基于欧氏距离的聚类算法。该方法将目标大小范围内的所有雷达探测点视为一个聚类。为该聚类分配一个中心距离和速度,该距离和速度等于所有聚类检测距离和速度的平均值
激光雷达点云数据处理
-
第一步:数据下采样和滤波
- 激光雷达点云数据数据量巨大,为了适应算力和实时性要求,需要适当降低数据量
- 利用立体像素网格(voxel grid),我们在(point cloud data,PCD)中定义了一个立方体素,并且每个体素只分配一个点云。
- 下采样之后,我们利用ROI(region of interest)来将超出这个范围的PCD给过滤掉(就是过滤掉不是路面的物体例如楼房)。
- 在后续的步骤中,我们将过滤后的PCD分割为道路和障碍物
-
第二步:PCD分割
- PCD分割在点级别上进行,十分耗费计算资源,所以我们需要进行处理
- 类似于雷达数据,我们将障碍物和它们附近的点(欧式距离)集群,并且给每个群一个新的位置坐标(x,y,z),这个坐标是群内所有点的坐标的平均值。最后,我们定义群大小的bounding box的尺寸,并且利用这个box来将障碍物进一步可视化。
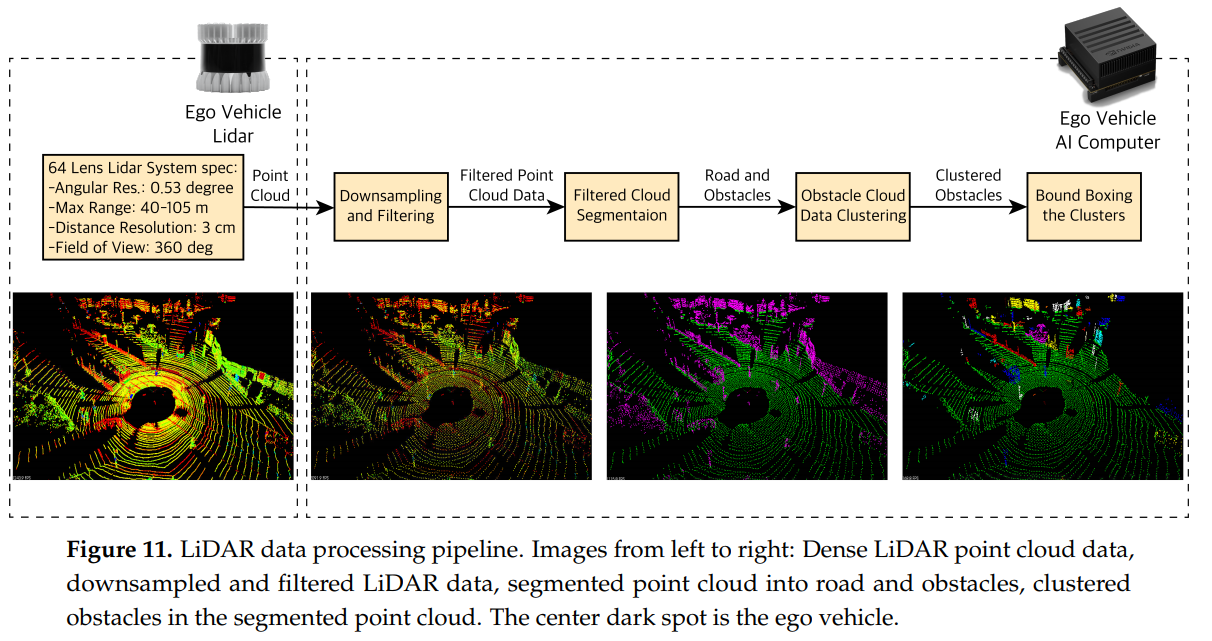
为了将PCD分割为道路和障碍物,我们需要找到道路平面,我们利用随机取样共识Random Sample Consensus(RANSAC)[39]。在每一步,RANSAC都会从我们的点云中选取一个样本,然后用一个平面穿过它。我们认为道路点是inliers和障碍点是outliers。它测量inliers(属于道路平面的点)并返回该平面,即具有最高inliers数量或最低离群值(障碍)数量的道路平面。
RSNSAC实在有点不好理解,已附上原文:
At each step, RANSAC picks a sample of our point clouds and fits a plane through it. We consider the road points as inliers and obstacle points as outliers. It measures the inliers (points belonging to the road plane) and returns the plane i.e., road plane with the highest number of inliers or the lowest number of outliers (obstacles)
拓展kalman滤波
在利用FCNx进行道路语义分割后,本节我们利用EKF实施单目标跟踪。
-
一个标准的KF包括三个步骤:初始话,预测和更新。
-
传统的KF处理不了非线性模型,非高斯噪声,我们用了EKF
-
LiDAR:得到位置Px,Py
-
radar:得到位置Px,Py以及速度Vx,Vy ;但是是在极坐标系下。
-
我们需要将笛卡尔坐标系转换为极坐标系,得到非线性的H
Experiments Procedure Overview
Experimental Results and Discussion
Conclusions
基础知识
- 全卷积神经网络FCNx
- FCN8
- 跳跃卷积层
- downsampling and upsampling
- 交叉熵
其他参考内容
-
介绍了有关毫米波雷达测距测速的相关基础知识原理,和本论文所讲的这方面内容比较重合,作者william是一名自动驾驶全栈工程师